
中国头部智驾厂商小鹏汽车的掌门人何小鹏曾经发表过一个观点,端到端只能实现L3,端到端+大模型才能实现L4。这是严谨的技术研判,还是拍脑袋的一家之言?
01
偷换概念,固然有利于产品的宣传,却有可能把大家的认知搞得一团糟。端到端成了自动驾驶行业最火的营销热词,没有之一。
大模型破圈效应更大,GPT的逆天实力东一句、西一句地多次灌到普通消费者的耳朵里。
端到端大模型的概念被少数车企和智驾方案商宣传了好长一段时间,在从业者群里逐渐变得耳熟能详。

不过,当前的自动驾驶系统能力确定无疑地处于L2++阶段,既然端到端+大模型才能实现L4,“端到端大模型”这个概念便有偷梁换柱之嫌。
实际上,端到端和大模型确实是两个不同的概念。
谈概念,就要一竿子扎到底,回到技术的原点去看一看。
与端到端相对的是规则+算法的分模块方案。
与传统的分模块方案相比,端的端方案有两个最根本的不同点,一则是传统的分模块自动驾驶系统划分为感知-决策-执行三个模块,每个模块之间都有非常明显的界限。

二则是传统方案是规则加算法,端到端方案是全面AI化、模型化。

与生成式AI大模型相对的是基于判别式AI的小模型。
这两者的区别在于判别式AI属于判定模型,它的基本原理是从大量的训练数据集中学习并总结出决策边界,从而预测数据的标签。
比如说,在BEV的视角下,行人、二轮车、三轮车、乘用车、大卡车、锥桶……每一个事物的种类都分得明明白白。

生成式模型则是估计各种类型的数据分布,比较不同类型下生成数据的概率,它的侧重点在于生成新的数据。
比如,正慢慢变得火热并有望在2025年成为自动驾驶行业最火营销热词的世界模型,它的主要作用就是生成在不同的驾驶策略下的摄像头视角。

再进一步总结一下,端到端是系统结构形式从规则向AI的转换,大模型是AI从判别式AI向生成式AI的转变,很明显是两种不同的概念。
02
没有调查就没有发言权。
一家车企或智驾方案供应商要在传统端到端方案之外开辟第二战线,上马生成式AI大模型这种特别消耗人力、物力、金钱、时间的新技术,肯定经过了非常仔细缜密的调研。
传统端到端之所以要+大模型,必定是因为大模型能够解决现有方案无法解决的痛点。
毕竟,大部分公司都在亏钱,不至于像西红柿首富那么豪横,非要把钱花在刀把上。

在2023年的CVPR会议上,小鹏汽车自动驾驶高管分享过在广袤的中国大地上做自动驾驶需要克服的三方面挑战:层出不穷、无视交通规则的交通参与者,复杂难解、特别考验空间几何能力的道路拓扑,任性且魔性、神鬼莫辨的交通标识。
这三个方面的挑战或痛点,端到端方案来了也只能望洋生叹。

传统的端到端方案固然可以消除冗余,通过对计算资源的集约化使用增加车端神经网络的参数量。
但是,即便是参数翻倍,也解决不了上面三个挑战。
车端模型都是由云端模型压缩而来,参数量有着几十倍的差距,云端模型好使的话,萝卜快跑也不用配备云端驾驶员了。
因为,参数翻倍是无法实现从感知能力到认知能力的升维。
比如对于第一项挑战-人车混杂的城区交通场景中的动态物体,比识别物体种类更加重要的是,能否建立足够的通用认知能力,并通过对长时序信息和当前交通环境下复杂语义信息的捕捉理解交通参与者的意图。

至于包含各种颜色、图案、数字、文字信息且形状各异的交通标识,就更加让人抓狂了,没有大语言模型的通用理解能力,小模型注定在各种长尾面前无能为力。

所以,无论是对交通参与者的意图理解,还是对繁杂多变的交通标识的语义理解,都需要仰仗生成式AI大模型超强的理解能力,才有可能解决这些感知长尾和决策长尾。
03
鲁迅先生说,这世上本没有路,走的人多了,也就有了路。在端到端大模型这条路上,已经有了越来越多的选手。
蔚来、小鹏、理想们纷纷将生成式AI大模型搬进车端自动驾驶系统里。

龙生九子,各有不同,正如各家的端到端模型架构各有千秋一样,蔚小理在自动驾驶大模型上做出了各自的技术选择。
或许是因为有4颗Orin X芯片在手,算力比较从容,又或许特斯拉选择了世界模型这条路线,在自动驾驶大模型上,蔚来汽车的世界模型成了蔚小理三家方案中最为硬核的存在。
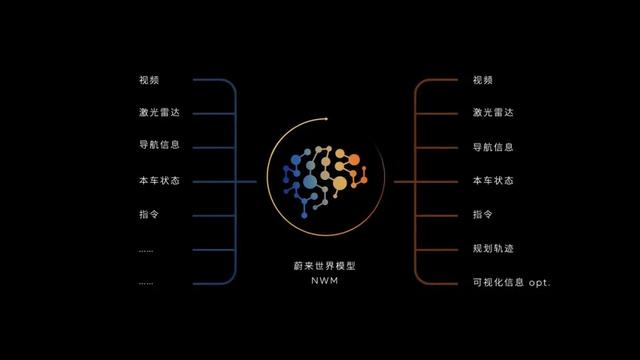
它的基本原理是根据车端传感器采集的当前视频数据、本车状态和对其它交通参与者意图的判断,推演左转、直行、右转后的场景,根据安全、舒适、效率最大化、社会影响最小化的策略,选择一条最佳的行驶轨迹。

小鹏的大语言模型体现在其端到端方案中的XBrain模块上面,对应去年在CVPR会议上痛陈的那几个挑战,它可以用于对动态物体的意图判断、对路牌文字、待转区交通标识的识别。

7月初,理想汽车召开智能驾驶发布会,宣布推送分段式端到端无图NOA,并发布了“本土首个”一体式端到端方案,并且“行业首创”端到端+视觉语言模型的双系统方案。
这里的视觉语言模型就是叠加了视觉模态的大语言模型。值得一提的是,在国内车圈,发布绝不等同于推送。

从理想汽车展示的视觉语言模型的能力来看,其作用和小鹏汽车的XBrain有异曲同工之妙。
在这三家的方案中,蔚来汽车含金量最高。世界模型涉及到对时空的理解和对物理规律的理解,本质上是三维空间智能,空间智能正是AI教母李飞飞的创业方向。

小鹏和理想汽车方案的本质依然是一维文本智能,和世界模型背后的空间智能不可同日而语。
李想6月份高调公布了理想汽车在智能驾驶上的目标-一年内实现L3,三年内实现L4。
做一下阅读理解,李想认为,端到端可以实现L3,端到端+视觉语言模型可以实现L4,和何小鹏的观点可谓不谋而合!
