生成式AI时代,数据能力成为企业差异化竞争的关键。
“每家企业都可以用业界最好的基础大模型,但差异化来自如何利用自身数据构建具有真正商业价值的生成式AI应用。”近日在一次沟通会上,亚马逊云科技大中华区产品部总经理陈晓建这样表示。
目前,检索增强生成(RAG)、微调、持续的预训练,是企业应用大模型的主要方式。在这些核心场景中,数据是绕不开的关键,尤其是当企业希望量身定制垂直领域的AI应用时。
要打造更懂业务的生成式AI应用,企业需要具备哪些数据能力?在帮助各个行业、各种规模的企业打造数据基座方面,亚马逊云科技分享了自身的经验与技术工具。

要做好微调和预训练,企业需要解决三个主要的数据问题:找到合适的存储方案来承载海量数据;清洗加工原始数据为高质量数据集;高效的数据治理。
在存储方面,海量的多模态数据和存储性能是企业的核心挑战。微调和预训练使用的数据往往都在TB甚至PB级别,而且文件格式多种多样,需要进行抽取处理转换。同时,微调和预训练大模型需要极高的存储性能。从而避免因为数据传输瓶颈造成高昂计算资源的浪费,或是吞吐量瓶颈导致更长的训练时间。
亚马逊云科技对象存储服务Amazon S3能够应对企业运行大数据分析、人工智能 (AI)、机器学习 (ML) 和高性能计算 (HPC)等存储需求。通过对冷、温、热数据的智能分层,Amazon S3可以大幅降低数据存储成本。目前亚马逊云科技上超过20万个数据湖都使用了Amazon S3。
文件存储服务Amazon FSx for Lustre能够提供亚毫秒延迟和数百万IOPS的吞吐性能。LG集团的AI研究中心LG AI Research借助Amazon FSx for Lustre加速模型训练,降低了35%的成本。
预训练模型时,数据清洗加工的过程非常复杂且耗时,包括数据收集、数据清洗筛选、数据去重、分词等步骤。以公开搜集的2TB英文数据集为例,经过清洗、去重后变成1.2TB的数据,再经过分词处理才能变成大约3000亿的tokens。
无服务器数据集成服务Amazon Glue可以更快地集成数据,连接不同数据源并简化相关代码工作。大数据服务Amazon EMR serverless能够更快地运行大数据应用程序和PB 级数据分析,并且成本不到本地解决方案的一半。
在数据治理方面,企业需要跨多个账户和区域高效查找数据,并进行精准的数据访问控制。
Amazon DataZone让企业能够跨组织边界大规模地发现、共享和管理数据,并通过统一数据管理平台对多源多模态数据进行有效编目和治理。

前面提到的数据存储、加工与治理,只是使用大模型的基础准备工作。
基础模型自身有较大的局限性,比如缺乏垂直领域专业知识、缺乏时效性、幻觉问题,以及用户隐私数据的安全问题等。因此,只有让企业私有数据与大模型相结合,才能让大模型解决业务问题。
试想一个场景,一家保险公司想要针对客服场景开发一个对话智能体。当一个新客户咨询“我想购买汽车保险”时,对话智能体能够自动推荐产品。这就需要大模型了解企业的保单产品和报价体系,理解用户画像和上下文语义等等。

这背后离不开检索增强生成RAG能力。RAG首先将不同类型的源数据通过分词处理和向量化,存储到向量存储中,再执行语义相似度搜索,匹配提示词中语义相似的上下文。
这一过程中,向量数据存储是非常关键的。最理想的情况,是将向量搜索和数据存储结合在一起。这样企业无需添加额外的组件和费用,也无需迁移现有数据,就能实现更快的向量搜索。
目前,亚马逊云科技已经在八种数据存储服务中添加了向量存储与检索功能,帮助企业更低成本使用RAG能力。
将数据存储服务和向量检索能力相结合,能够发挥二者优势互补的作用。
以制造业中被广泛应用的知识图谱为例,知识图谱擅长结构化知识,但不能理解自然语言,只能做严格推理。基础模型正好相反,能够理解自然语言但缺乏专业知识。两者结合可以获得更精确的专业知识以减少幻觉,也可以对不准确的回答进行溯源和纠偏。

在生成式AI应用开发方面,基础模型缓存与无服务器数据服务,能够大幅降本增效,让企业集中精力于AI业务创新。
对于一个生成式AI应用,如果频繁调用基础模型将会导致成本增加和响应延迟。相对于数据库调用通常毫秒级甚至微秒级的响应时间,基础模型每次调用时长往往达到秒级。
而很多时候,终端用户大部分问题是类似甚至重复的。通过缓存给出回答,不但能够减少模型调用,还可以节约成本。
Amazon Memory DB内存数据库本身就是一个高速的缓存,同时也支持向量搜索。它能够存储数百万个向量,能够以99%的召回率实现每秒百万次的查询性能。这对于欺诈检测和实时聊天机器人等场景至关重要。
此外,相比自建数据库和托管数据库,无服务器数据库服务能够帮企业最大限度减少复杂的运维工作,并根据需求快速扩缩资源。
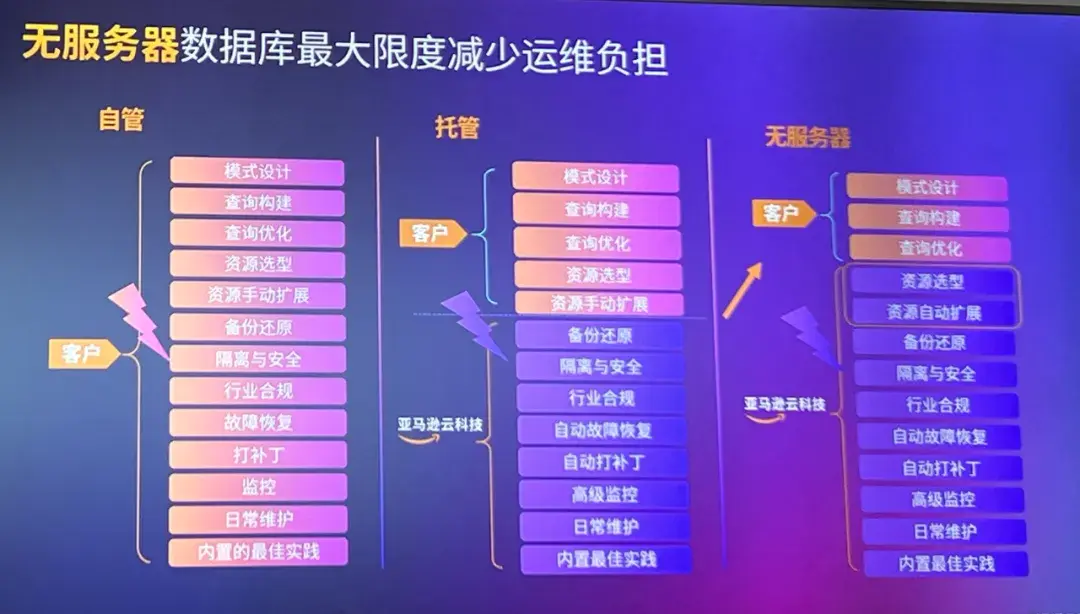
综上,构建生成式AI应用,一切要从数据做起。
只有当企业将自身数据与基础模型结合,构建出具有独特价值的生成式AI应用,才能打造出“数据-模型-应用”正向循环的数据飞轮。
END
本文为「智能进化论」原创作品。
