哈喽,医学er们,今天继续给大家分享临床预测模型经典文献~
今天分享的这篇很经典,有很多值得我们学习的地方。
题目:Predicting survival and neurological outcome in out-of-hospital cardiac arrest using machine learning:the SCARS model
🟢这篇文献作者把不平衡问题考虑得很全面,而且出现了众多预测的关键且容易出错的问题。
(1)降采样解决不平衡
(2)采样技术只能在训练集使用
(3)阈值调整也可解决类别不平衡
(4)阈值调整只能在训练集上使用
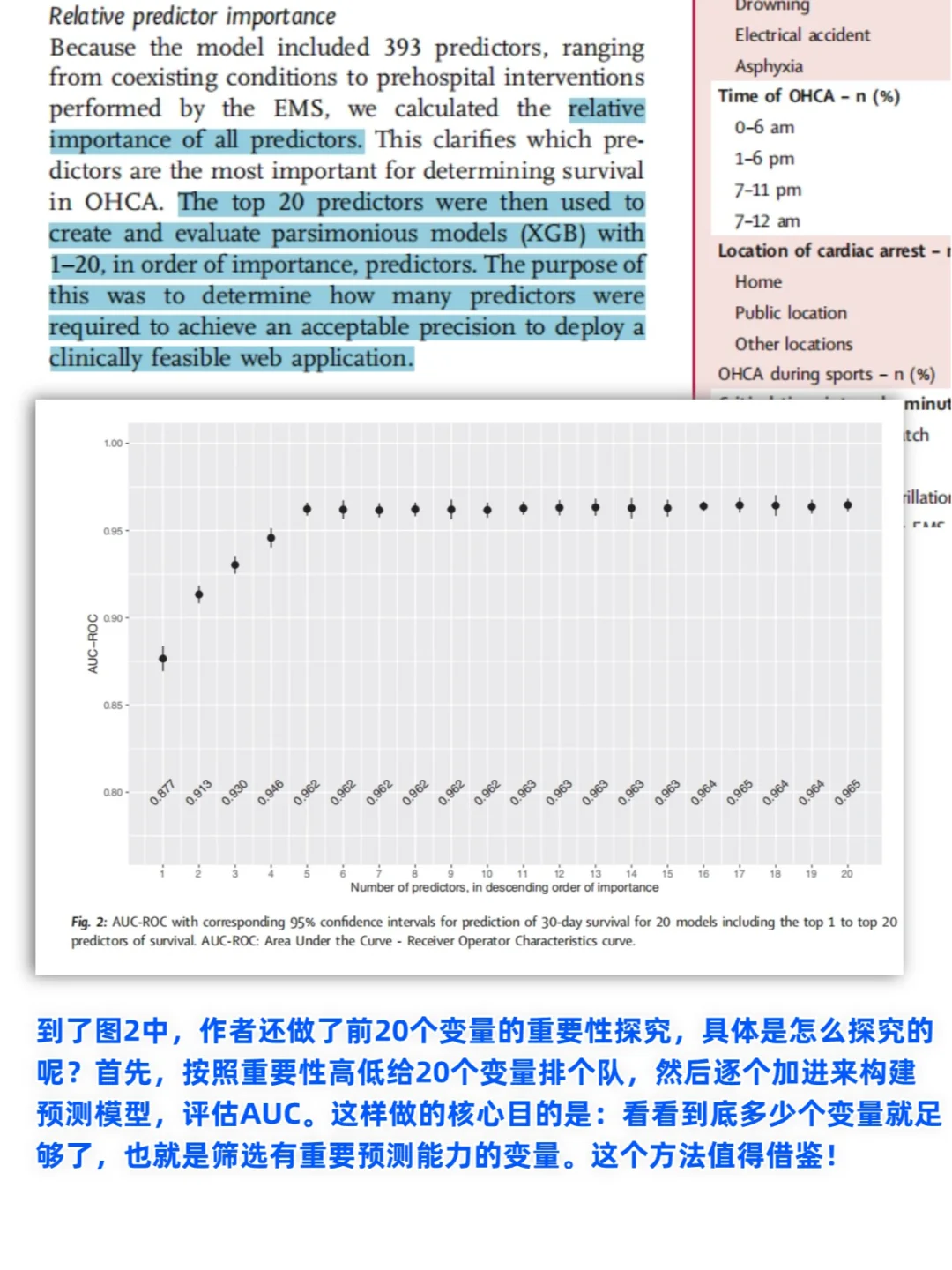
🟢很有新意的变量重要性测度
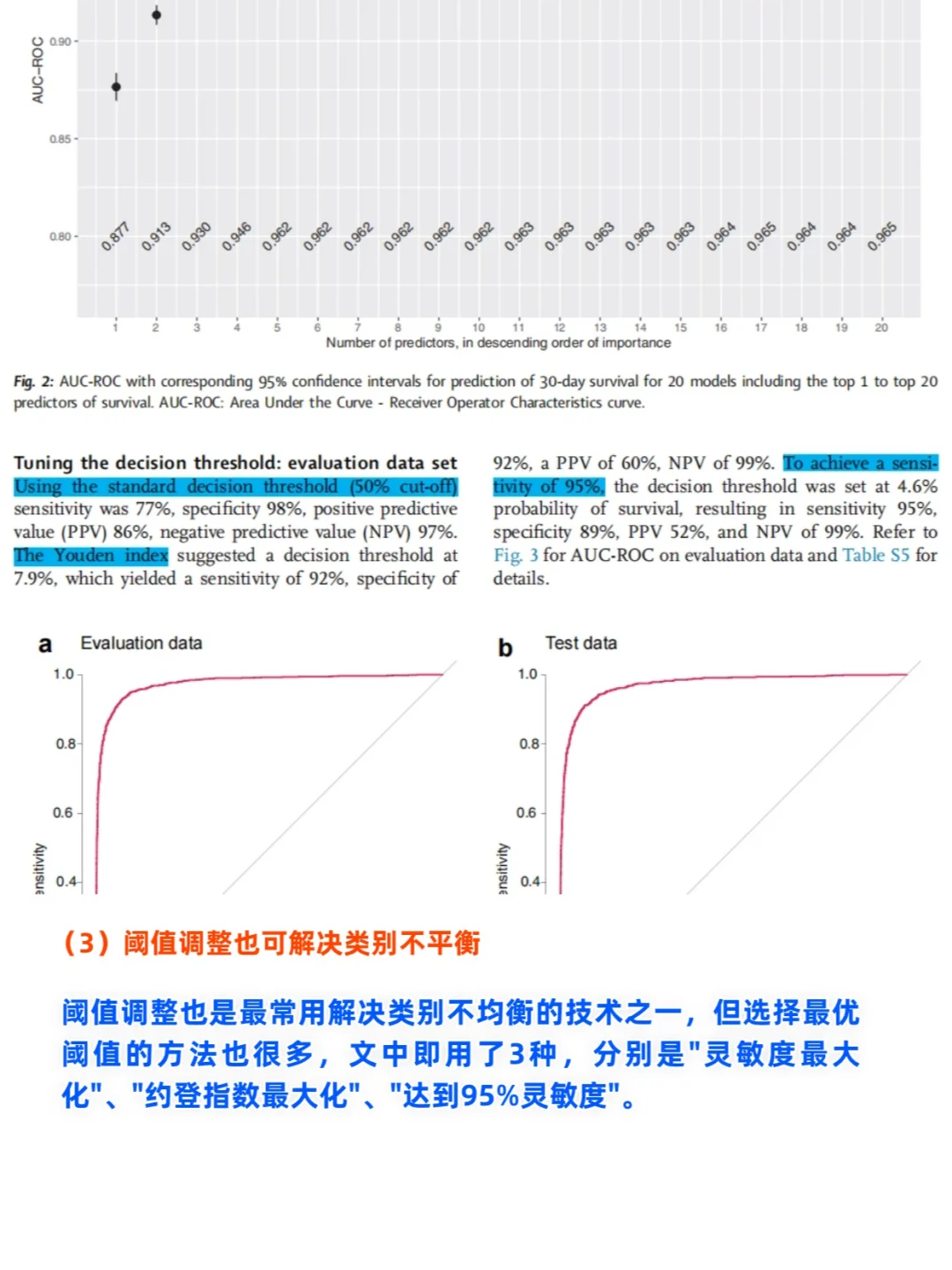
变量重要性测度是一个常见问题,本文中作者却给我们带来一些新思路。如上左图,作者给出的是具体变量“自高到低”的重要性排序;但右侧图是什么呢?仔细一看,原来是按照大类给出的重要性,这个很有意思,也蛮有新意。也就是说,左侧是具体到变量水平,而右侧是放在大类水平。
(具体解析看上图噢~)
🙋♀️PS:如果你今年也想写一篇临床预测模型,但是毫无头绪,又没有数据!那么建议你挖掘公共数据库!一一MIMIC重症数据库!
✨因为MIMIC重症数据库数据量庞大且质量可靠,适合所有科室。为忙碌的医学生/小医生提供了性价比超高的发文途径。
💥统计之光专门为大家开设了“MIMIC实战挖掘”直播小课(30人),让你少走弯路,系统学会MIMIC数据库挖掘,结合自身情况,灵活运用。
直播主讲老师薛老师,是统计之光临床一对一的金牌讲师,与0基础学员接触时间长,很懂科研小白们的痛点。所以她讲课细致易懂,深受学员们的喜爱!
此次直播授课为6周,授课完另有6周答疑课,专门解决学员实操的答疑,此外从开课日起薛老师还会持续12周的社群答疑,所以不用担心学不会!
👉4月12号开课,火热报名中~🍎888→了解更多详情~