魔女团新闻
首页
推荐
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
健康
房产
家居
电影
星座
旅游
健身
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点
首页
科技
辅导男朋友转算法岗第32天|DPO
奔跑的跳跳
2024-09-08 17:33:36
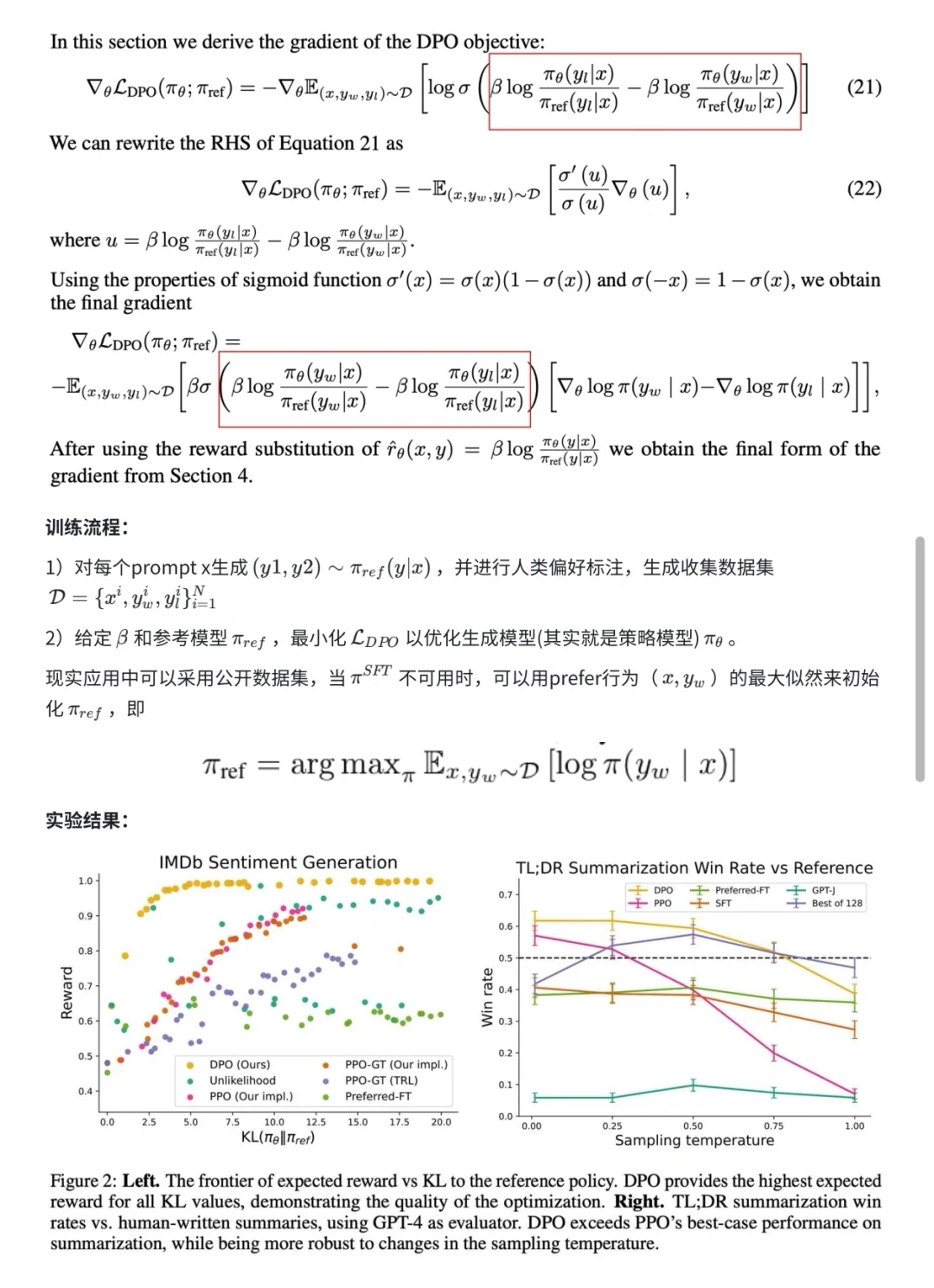
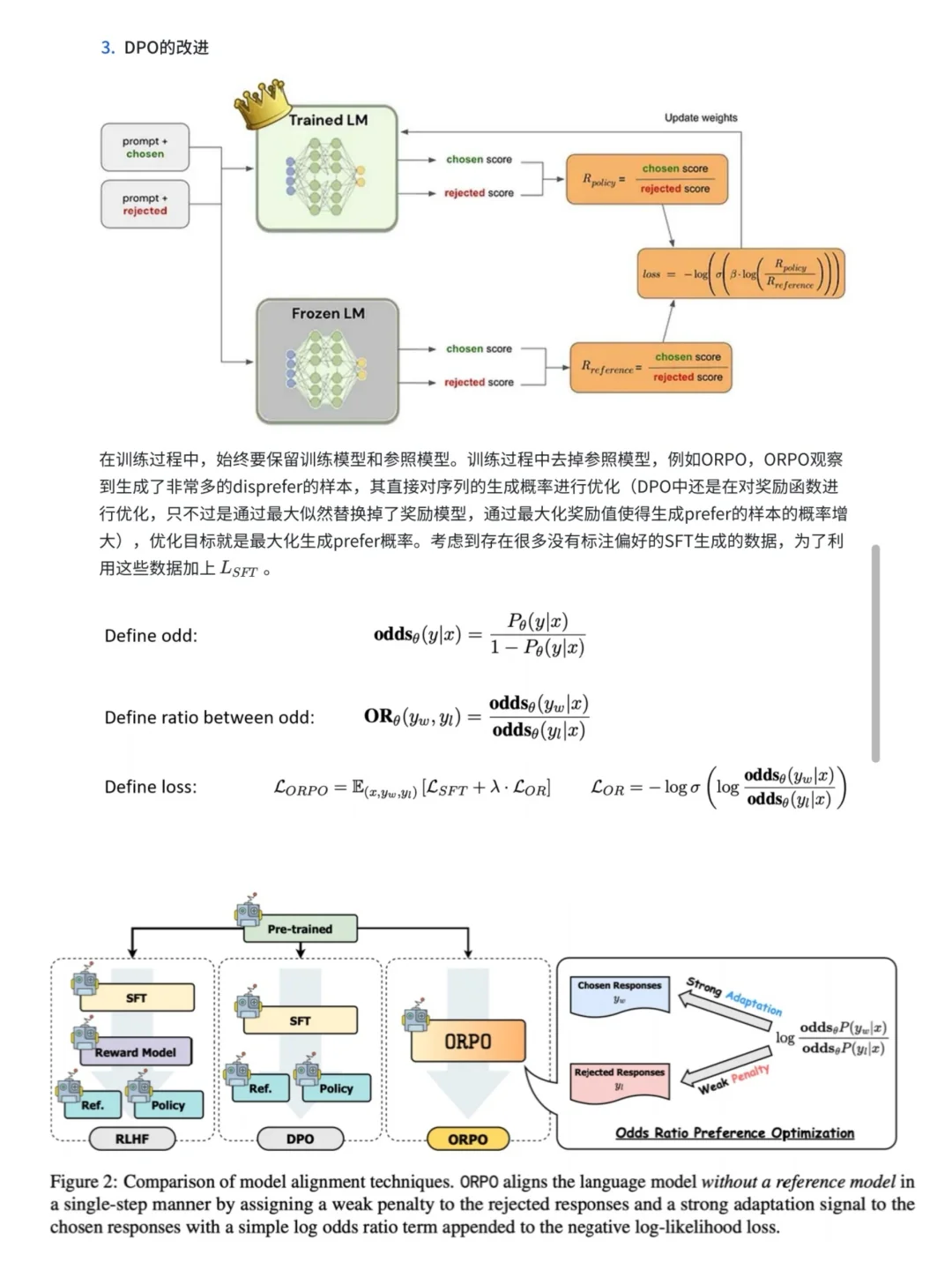
终于到DPO了,谁懂! 基于人类反馈的强化学习RLHF分三个阶段:SFT、奖励模型(RM)、强化学习(PPO)。但是PPO复杂且不稳定,因此现实场景下多使用DPO:不依赖于明确的奖励建模或者强化学习,通过直接优化用户的偏好反馈来提高策略的表现。 [睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R][睡觉R] AAAI赶不上了,ICASSP启动!
0
阅读:0
评论列表
舞潇潇
2
2024-09-08 20:24
你这个笔记能不能开园啊大佬
饿死我了
1
2024-09-08 20:37
ICASSP太危险了,不投
右岸
1
2024-09-08 21:15
[doge]ICASSP不是点击就送嘛
奔跑的跳跳
简介:感谢大家的关注
热门分类
推荐
军事
NBA
体育
社会
明星八卦
娱乐
财经
科技
汽车
历史
国际
游戏
动漫
公益
搞笑
商业
互联网
数码
国际足球
健康
房产
家居
电影
星座
旅游
健身
时尚
科学探索
职场
育儿
股票
教育
影视
情感
热点




你这个笔记能不能开园啊大佬
ICASSP太危险了,不投
[doge]ICASSP不是点击就送嘛