基于可解释机器学习揭示城市密度与健康风险的关系
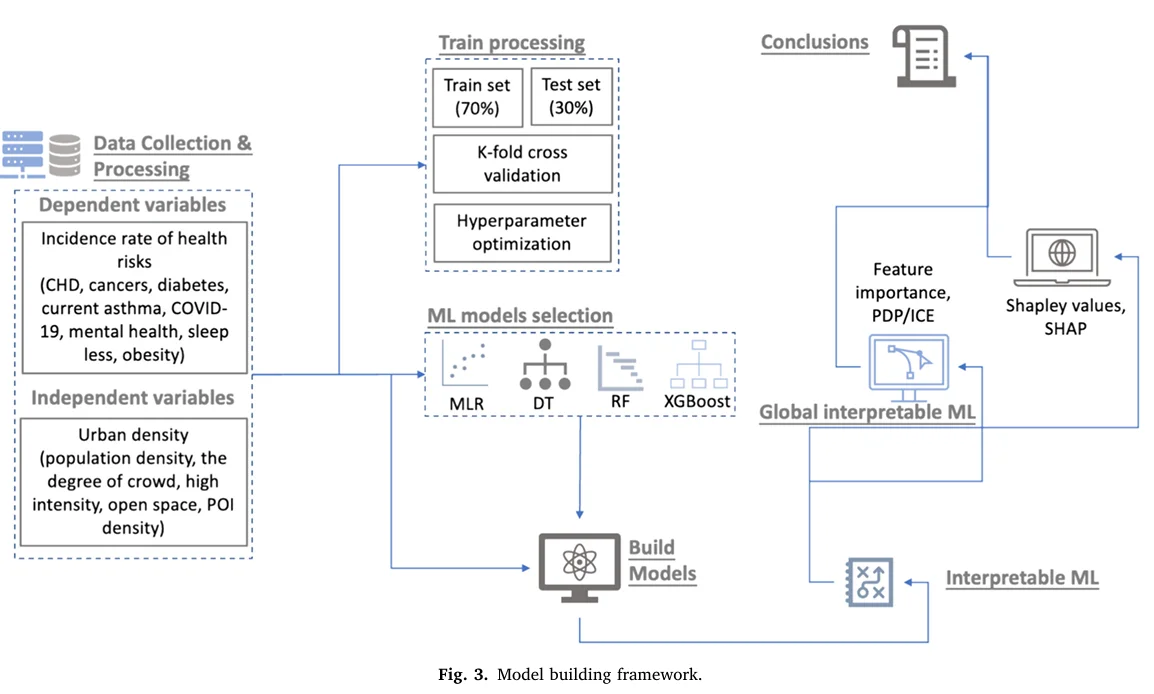
在本文中,提出了一种基于机器学习(ML)的方法,用于理解非线性和复杂关联,并在美国大都市地区的案例中得到了验证。多种可解释的方法被用于解释机器学习模型的决策过程。通过全面研究多种健康风险及其与城市密度的关联,本研究获得了一些有价值的发现,有助于回答城市密度与健康风险之间关系和机制的问题。
我们的工作为至少两类观点提供了有力的证据。首先,我们证明了城市密度与健康风险之间的关联并非社会经济因素的附带产物,城市密度本身确实对人类健康有显著影响。其次,我们发现健康问题与环境之间的交互程度可能是区分关联模式的重要线索。交互程度的增加可能导致密度指标的负面影响。具体而言,对于不同类型的疾病,长期慢性疾病往往与高密度开发空间的比例呈现负相关关系,而短期传染病,如健康负担和心理健康问题,则往往与人口密度和活动相关密度因素呈现正相关。对于同类型的疾病,如慢性病,长期且积累效应更强的疾病(如冠心病、糖尿病和癌症)在密度增加时往往表现出更明显的负相关趋势,相较之下,短期且积累效应较弱的疾病(如哮喘)则受兴趣点密度的影响更大。此外,这些关系是非线性的,尤其是在人口密度因素上,表现出明显的调节点。虽然特征之间的交互可以在一定程度上解释这些波动,但我们无法确定这些波动源于现实情况,还是模型的误判。
显然,这里讨论的发现只是冰山一角。该研究仍存在一些局限性。首先,尽管我们从人口、建成环境和活动角度定义了城市密度,但由于数据的限制,缺少了一些关键指标,如就业密度、土地利用多样性、道路网络和社会联系密度。其次,样本仅限于美国大都市地区,数据来源于几个公开渠道。需要更多研究来比较不同地区的差异,纳入动态因素,并研究广泛的健康问题。此外,背后的机制需要在人类行为、生物学、医学等领域进行更深入的思考。未来的研究可能会从临床实验的设计和实施中受益。