张晨,清华大学计算机系高性能所博士生,导师为翟季冬老师,主要研究方向为面向人工智能和量子计算的高性能异构计算系统。在OSDI、SC、ATC、ICS会议上发表一作论文,并获得ICS21最佳学生论文。曾获得SC19,SC20,ISC21国际超级计算机竞赛冠军。获清华大学本科生特等奖学金、国家奖学金、北京市优秀毕业生、北京市优秀毕业设计等荣誉。
2024年7月,清华大学计算机系PACMAN实验室发布开源深度学习编译器MagPy,可一键编译用户使用Python编写的深度学习程序,实现模型的自动加速。
尽管目前存在大量高性能的深度学习编译器,但是这些编译器均以计算图作为输入,需要由用户将编写的Python程序手动转化为计算图。为了避免这种不便性,该团队设计了MagPy,直接面向用户编写的Python+PyTorch程序,自动将其转化为适用于深度学习编译器的计算图表示,从而充分发挥深度学习编译器的优化能力,避免用户使用复杂Python语法带来的性能下降,为用户带来易用性和效率的双丰收。
该工作同时于系统领域重要国际会议USENIXATC’24发表长文,第一作者清华大学博士生张晨、通讯作者为翟季冬教授。PACMAN实验室在机器学习系统领域持续深入研究。MagPy是继PET、EINNET等工作后在深度学习编译器上的又一次探索。欲了解更多相关成果可查看翟季冬教授首页:https://pacman.cs.tsinghua.edu.cn/~zjd

研究背景:深度学习计算图提取技术
近年来,深度学习在生物科学、天气预报和推荐系统等多个领域展示了其强大能力。为了简化编程过程,用户倾向于使用Python编写深度学习模型,并在需要进行张量操作时调用如PyTorch等的张量库。此时,用户程序会在调用张量库时立即执行张量操作,如此不加优化地直接执行程序性能较差。另一方面,为了提升深度学习模型的运行速度,深度学习编译器倾向于使用以算子图的格式表示的深度学习模型作为输入,在计算图上进行图级优化,如图替换和算子融合。当可以获取到模型的计算图时,代表性的深度学习编译器TorchInductor和XLA可以在PyTorch的基础上平均加速模型1.47倍和1.40倍。
具体结果如图1所示,标记为Fullgraph-Inductor和Fullgraph-XLA。然而,实现这种加速的前提是用户手动将程序转换为计算图格式,这对许多模型开发者来说是困难的。尤其是随着深度学习的广泛应用,越来越多的模型是由化学、生物和天文学等领域的非专业程序员开发的。因此,迫切需要一种自动化方法将用户编写的Python程序转换为编译器友好的图格式来加速程序,这被称为计算图提取技术。
由于Python程序具有极强的动态性,加之用户程序存在行为的不确定性,现有的计算图提取技术在处理较复杂的用户程序时无法取得最优的性能,如图1中的TorchDynamo-Inductor(使用TorchDynamo提取计算图,使用TorchInductor编译)、LazyTensor-XLA(使用LazyTensor追踪计算图,使用XLA编译)所示。
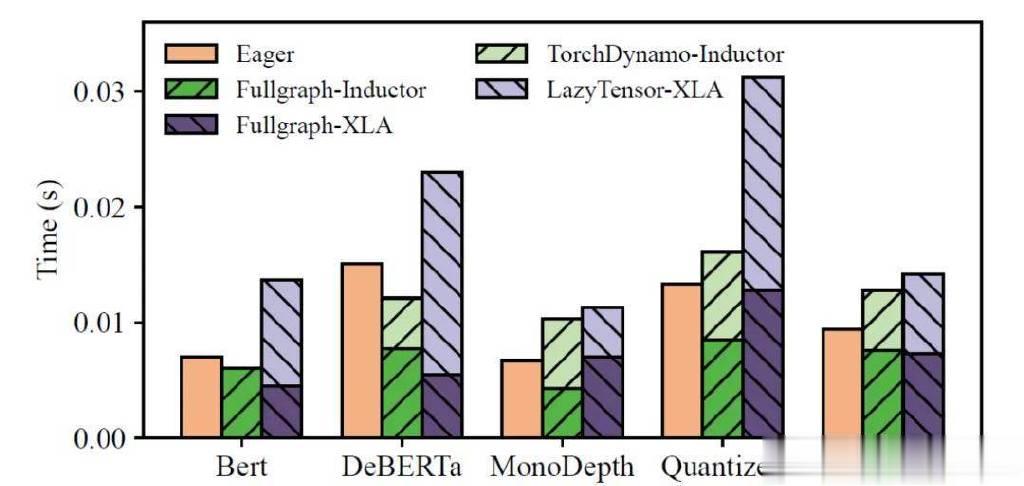
图1:深度学习编译器可以显著提升模型运行效率,但现有的图提取技术阻碍了这一点。图中Eager表示直接执行PyTorch程序,Fullgraph-Inductor与Fullgraph-XLA分别表示Inductor、XLA对模型的计算图进行编译后的加速,TorchDynamo-Inductor与LazyTensor-XLA分别表示使用TorchDynamo和LazyTensor技术从用户Python程序中提取计算图再进行编译的性能。
MagPy的解决方案
MagPy的核心思想是分析Python解释器中的执行状态信息,从而让编译器能够更好的理解用户程序。Python解释器能够准确支持所有Python特性,并在运行时保留了高层次的执行状态信息,如各个变量的类型和值等等。通过有效利用解释器提供的信息,能够更全面地了解程序的行为,从而更好地提取程序计算图。
MagPy的设计基于以下几点观察:
首先,大多数深度学习程序的动态性是有限的。尽管这些程序是用Python编写的,具有数据类型、控制流逻辑和运行时函数调度等潜在的动态特性,但其计算图结构在不同批次间通常保持不变。ParityBench是一个从Github上自动爬取超过100颗星的PyTorch深度学习程序组成的基准测试集,它的1421个程序中,83%的程序(1191个)均满足有限动态性的性质。对于这些程序,可以通过在程序执行过程中监控张量操作,较为简便地获取其计算图。根据这个性质,MagPy将计算图提取问题从分析“计算图是什么”简化为分析“得到的计算图何时会发生变化”。
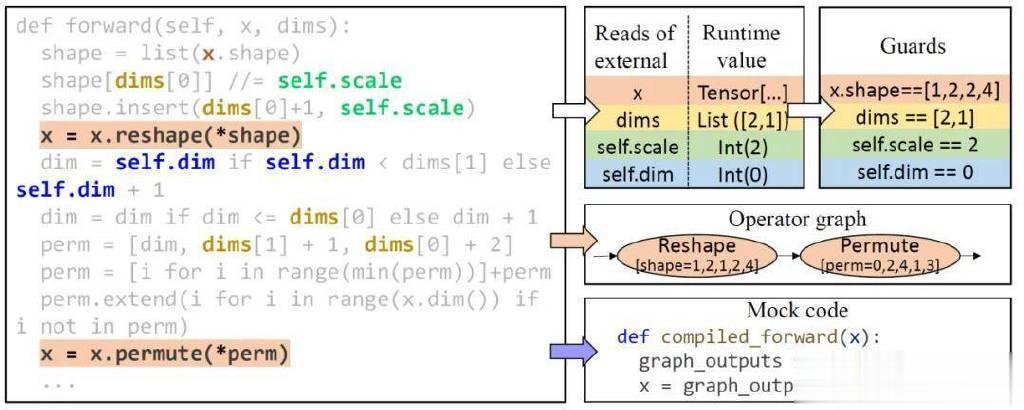
其次,只有外部值能影响程序行为。利用这一特性,可以更简易地检测出会导致计算图发生变化的因素。这里的“程序行为”包括计算图的结构和所有程序副作用(sideeffect)。只要程序从外部读取的所有值(如输入参数和全局变量)保持不变,且调用的函数的输出结果不具有随机性,程序行为就不会发生变化。因此,MagPy只需验证所有从外部读取的值都不变,即可保证计算图结构不变。例如,尽管图2中的程序使用了许多复杂的Python特性,但只要所有从外部读取的值(如x、dims、self.scale和self.dim,标记为粗体)与之前运行一致,计算图就保持不变。MagPy会首先运行一个“守卫函数”对于这些值是否发生变化进行检查(Guards),当检查通过时,MagPy将会运行一个“模拟函数”(mockcode),用以调用经过深度学习编译器编译的计算图及模拟程序的所有副作用(如示例中的对x进行赋值)。
第三,守卫函数和模拟函数都可以通过分析程序执行状态来确定。守卫函数的作用是验证新一次执行的输入状态是否与之前运行匹配,模拟函数的目的是重现之前运行的最终状态。这两个部分仅基于运行时状态,而不是用户程序的逻辑。Python解释器在解释执行程序的过程中,保留了所有需要的执行状态信息,因此不再需要具体分析Python复杂而动态的执行逻辑。守卫函数和模拟函数需要关注的变量包括显式读取或写入外部的值(如self)以及被它们引用的值(如self.dim)。因此,MagPy设计了引用关系图来记录和分析程序行为。
基于上述观察,MagPy提出了引用关系图(ReferenceGraph,简写为RefGraph)来记录程序执行期间的程序状态。MagPy定义了执行状态接口,用于在程序执行期间收集运行时信息,并使用基于标注的图更新规则来维护RefGraph。MagPy还提出了在RefGraph上进行遍历生成守卫函数和模拟函数的算法。具体细节可以阅读论文。
实验
MagPy具有极高的Python语言特性覆盖率,其在对ParityBench中1191个静态的真实用户程序进行测试时,成功将93.40%的程序转化为完整的操作符图,大幅高于现有工作TorchScript(35%)和TorchDynamo(77.2%)

由于更完整的计算图导出,MagPy在端到端测试中,也表现出具有竞争力的性能。下图展示了对于图像处理、自然语言处理等典型深度学习模型,MagPy取得的加速。MagPy可取得最高2.88倍,平均1.55倍的提升。实验在单张A100上进行,X-Y表示使用图导出技术X和图层编译器Y。









