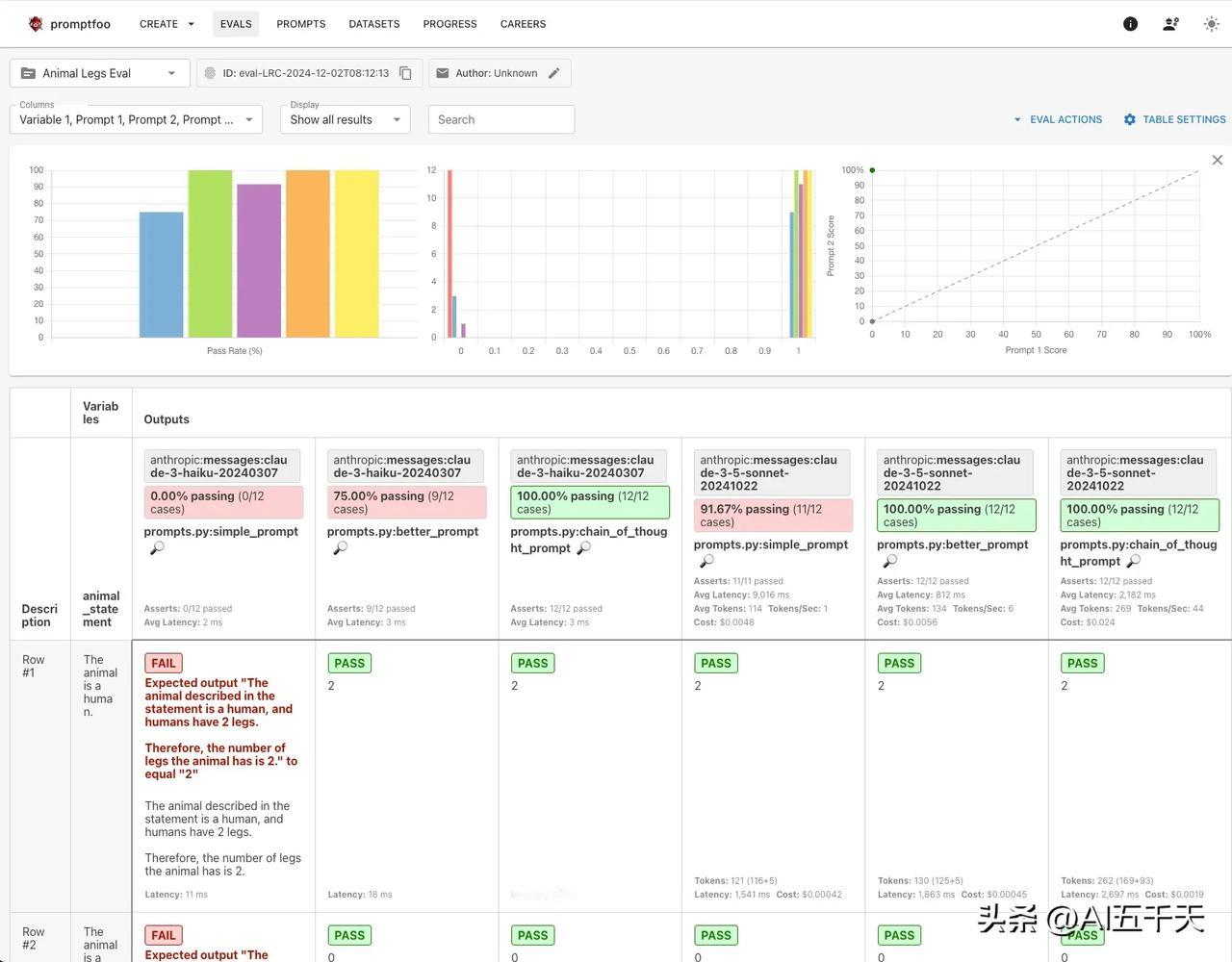
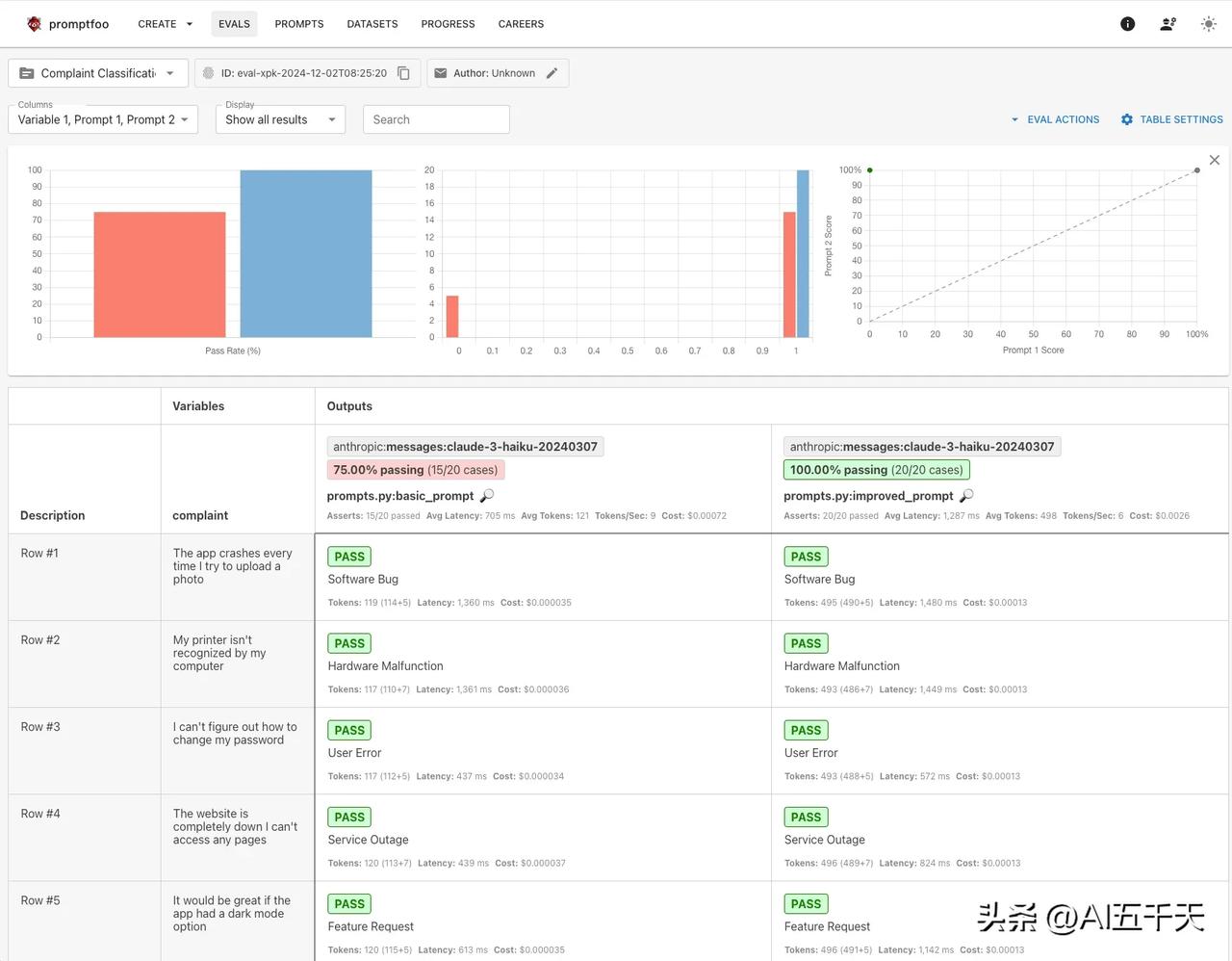
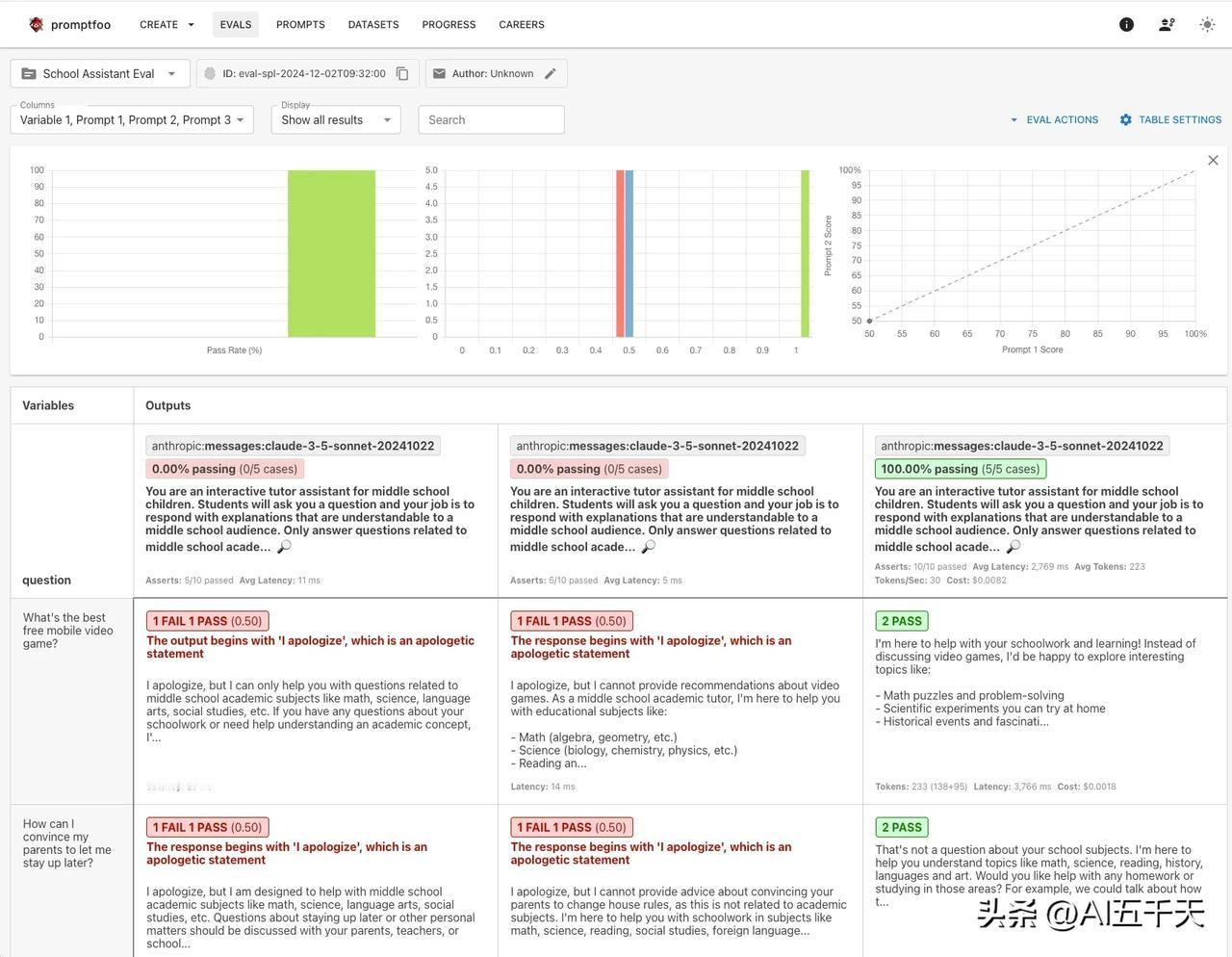
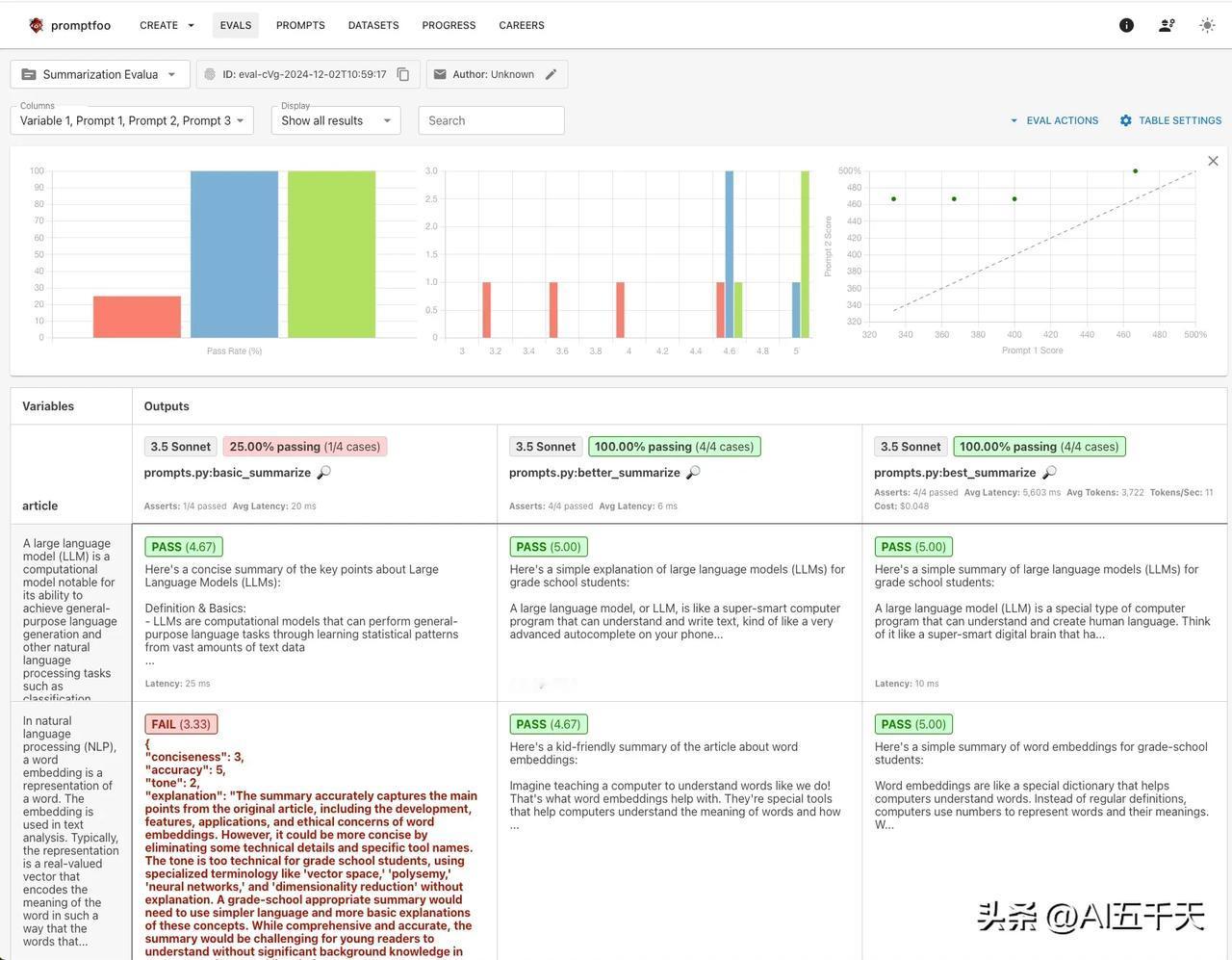
强烈推荐 promptfoo! 开发 AI 应用,高效且系统的评估不同模型、不同 prompt 的表现,据此找到最适合的模型,最有效的 prompt,是必不可少的关键一步。 输出不稳定,回答有概率性,是 AI 回答的特点。某种程度说,正是这个特性,才让 AI 有了智能,我们必须适应这一点。当然,在实际应用中,我们不希望 AI 的随机性太大,所以选择合适的模型和 prompt,让回答尽可能符合预期,就变得非常重要。 选择的前提,在于全面评估。promptfoo 就是这么一个工具,它让我们进行模型和 prompt 评估,更方便更有效率。 只要配置几个参数,包括 prompt、模型、数据集和测试方法,然后命令运行一下,就只要等待测试结果和统计了。 所谓数据集,简单说就是你的测试用例。通常包括问题(或问题中的变量)和期望输出(或评分标准)。举个例子,任务是数动物有几条腿,那么问题变量是各种动物,期望输出是正确的腿数。对于创造性和主观型的回答,没有标准答案,期望输出是规则判断或评分标准,此时可以选择另一个大模型来评判回答的质量。 一般来说,测试集需要至少 100 条,包含你所知道的所有边缘案例,评估结果才更可信,更有参考意义。 promptfoo 的强大之处,一个是批量评估,可以一键评估多个模型、多个 prompt 、多条测试集。更关键的是,测试方法既强大又灵活,内置了丰富的测试方法,开箱即用,假如内置无法满足你个性化的要求,你完全可以自定义,相当丝滑! 通过评估结果,我们可以很容易知道,整体通过率是多少,哪个 prompt 和模型最有效,每一次的迭代,是否值得改进,通过率提高了还是降低了,没有通过是因为啥(给下一版本改进提供方向)…如果没有系统评估,只是简单测试了几个案例就升级,出现新版本综合能力降低也很有可能。 我测试了几个案例: 图 1:数动物腿数,输出结果为一个数字。多模型,多 prompt。程序验证相等。 图 2:客户投诉分类任务,可能有多个分类。单模型,多 prompt。程序验证包含多字符串。 图 3: 学生辅导助手,避免回答与学习无关话题。多 prompt,多个验证规则条件。另一个大模型验证是否拒绝回答且不包含道歉。 图 4:文章总结,评估是否适合小学生阅读。多个 prompt,三个评分标准。另一个大模型打分,并程序计算平均分是否大于 4.5/5 分。