昨天字节火山引擎发布了豆包视觉理解模型。讲真,这可比单纯对话聊天什么的好玩多了。向它「投喂」图片,就能让模型看图识别、做题、写小作文。什么传世名画、电影截图,都能给出溯源结果,简直就是加强版的电商「搜同款」,以后再也不怕遇到剪片不留名的作者了。这要是以后能和AR眼镜相结合,简直是萌王同款的智慧之王能力。
从提升模型智能水平来说,学界很多声音不看好视觉理解大模型。一个关键点是,语言大模型以语言为基础,而语言自身就是一种人类智慧加工品,具有离散性的同时又自成系统,生成通用大模型有着天然优势。相比之下,视觉图像的连续性难以提炼出共性,很难让机器智能举一反三,更别提各种物理规律的识别。
但是确实有很多应用需要视觉理解,它能大大降低人和大模型之间的交互门槛,也能增加很多用语言无法描述的应用场景。比如在医学影像领域,帮助医生减轻看片子的压力;电商营销基于图像的创作、找同款、推荐;在教育领域辅助阅卷讲题等等。
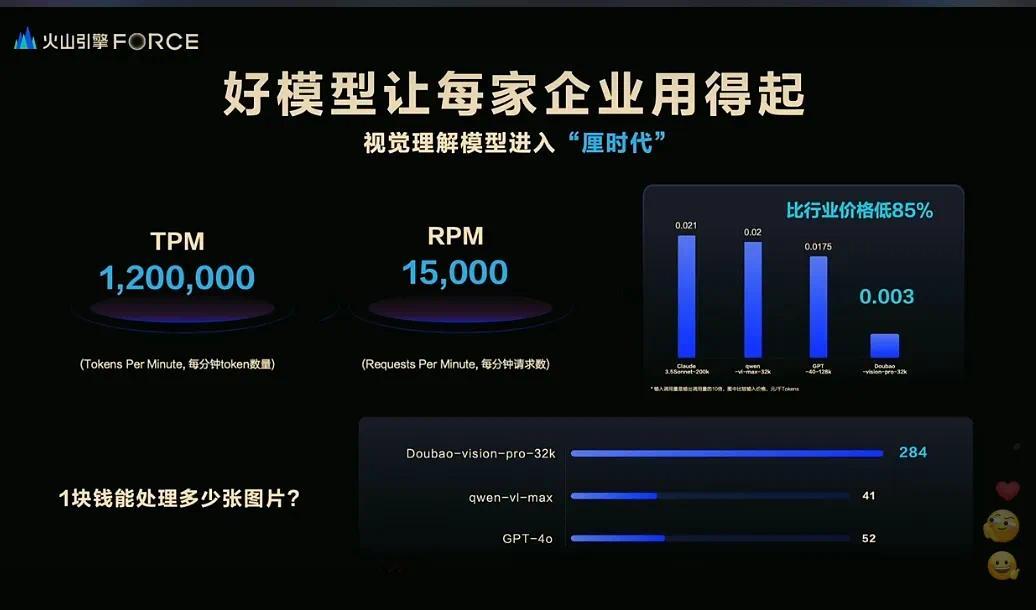
而豆包视觉理解模型,把费率干到了千tokens输入价格仅为3厘,相当于一元钱可处理284张720P的图片。相信这能够调动起开发者们和企业的使用积极性,让大家放手用起来,找到更多落地场景。