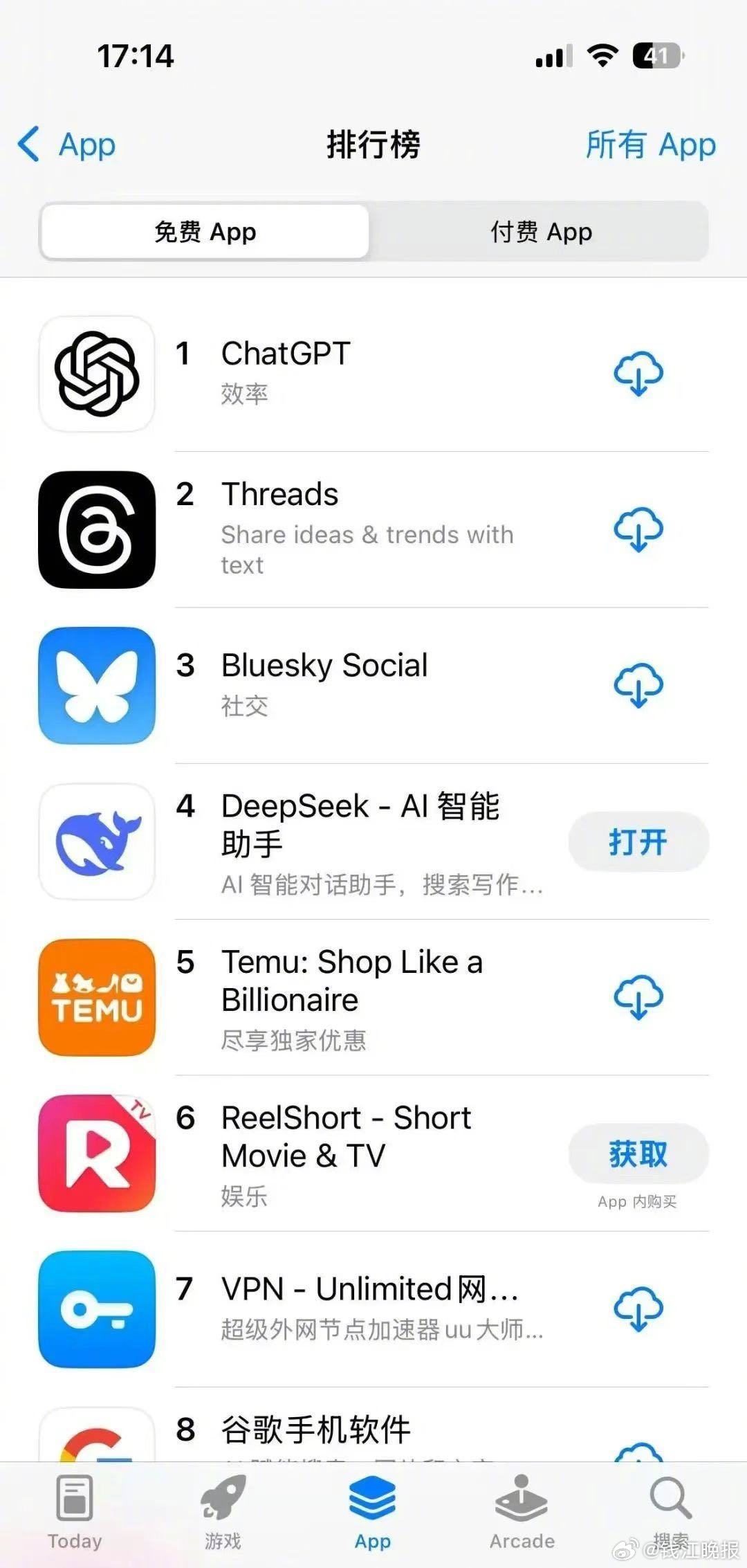
【#杭州的DeepSeek跻身美国App竞技榜前三#】“神秘东方力量”DeepSeek给硅谷带来的浪花,还在不断增强,刚刚,DeepSeek-R1跻身大模型竞技榜前三,与ChatGPT-4o齐名,超越Google Gemini、Microsoft Copilot等美国科技公司的生成式AI产品。
DeepSeek 因为其成本低廉但性能卓越的 AI 模型,引起了包括众多硅谷科技巨头在内的目光。
其卓越的性能在网友的实测中也得到了验证。在与R1展开的30场对抗中,DeepSeek胜率超过了80%。
去年年底,DeepSeek推出开源模型DeepSeek-V3。当时,聊天机器人竞技场(Chatbot Arena)数据显示,DeepSeek-V3在所有模型中排名第七,在开源模型中排第一,是全球前十中性价比最高的模型。
DeepSeek-V3大模型的核心技术创新是其迅速崛起的关键。该模型融合了Multi-head Latent Attention(MLA)、混合专家架构(MoE)和FP8低精度训练三项技术,显著提升了性能与效率。
而在本月20日,DeepSeek又正式开源R1推理模型。1月24日,DeepSeek-R1在Chatbot Arena综合榜单上排名第三,与OpenAI的顶尖推理模型o1并列。在高难度提示词、代码和数学等技术性极强的领域,DeepSeek-R1拔得头筹;在风格控制以及高难度提示词与风格控制结合的测试中,DeepSeek-R1均与o1 并列第一。
更重要的是,DeepSeek-V3 的训练成本仅为558万美元,远低于如训练成本高达7800万美元的 GPT-4。并且,其 API 服务价格也延续了过往亲民的打法。输入 tokens 每百万仅需0.5元(缓存命中)或2元(缓存未命中),输出 tokens 每百万仅需8元。
最近,来自加州伯克利大学在读博士 Jiayi Pan 的研究团队更是成功地以极低的成本(低于30美元)复现了 DeepSeek R1-Zero 的关键技术——顿悟时刻。
《金融时报》将其描述为震惊国际科技界的黑马,认为其性能已与资金雄厚的 OpenAI 等美国竞争对手模型相媲美。Maginative 创始人 Chris McKay 更进一步指出,DeepSeek-V3 的成功或将重新定义 AI 模型开发的既定方法。
1月24号,一条发布在匿名平台teamblind上的帖子疯传。一名Meta员工称,现在Meta内部因为DeepSeek的模型,已经进入恐慌模式。
这位Meta员工写道:“一切源于DeepSeek-V3的出现,它在基准测试中已经让Llama 4相形见绌。更让人难堪的是,一家‘仅用550万美元训练预算的中国公司’就做到了这一点。工程师们正在争分夺秒地分析DeepSeek,试图复制其中的一切可能技术。
所以也难怪 Meta CEO 扎克伯格、图灵奖得主 Yann LeCun 以及 Deepmind CEO Demis Hassabis 等人都对 DeepSeek 给予了高度评价。
在海外,OpenAI CEO Sam Altman 刚刚也试图剧透 o3-mini 使用额度,来抢回国际媒体的头版头条——ChatGPT Plus 会员每天可查询 100 次。
DeepSeek,全称杭州深度求索人工智能基础技术研究有限公司,成立于2023年7月17日,是一家创新型科技公司,专注于开发先进的大语言模型(LLM)和相关技术。(潮新闻 记者 张云山)