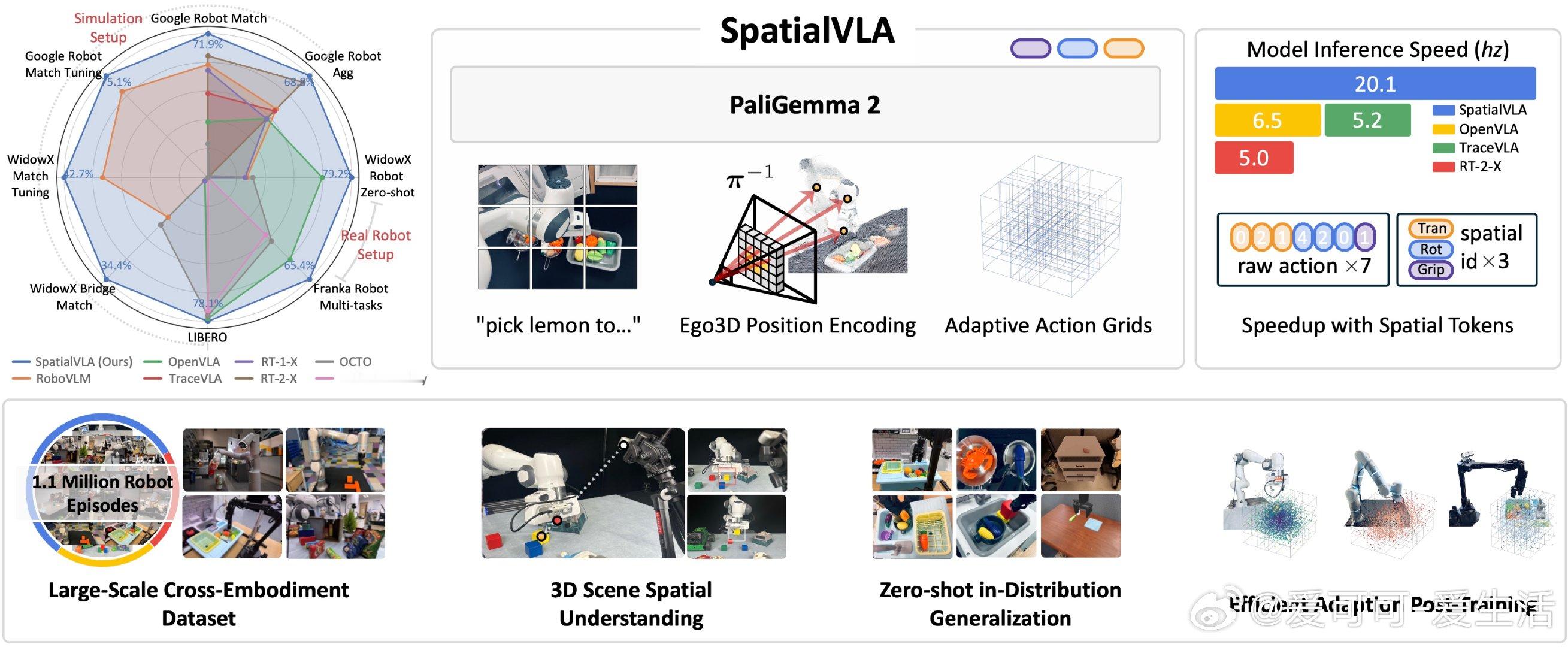
【[24星]SpatialVLA:一个强大的空间增强型视觉-语言-行动模型,专为机器人任务设计。亮点:1. 基于110万真实机器人场景训练,性能卓越;2. 仅需8.5GB GPU内存即可运行,部署简单;3. 在多种机器人任务中表现优异,零样本学习能力突出】
'SpatialVLA: a spatial-enhanced vision-language-action model that is trained on 1.1 Million real robot episodes.'
GitHub: github.com/SpatialVLA/SpatialVLA