R1 的论文里也提到,使用R1-Zero 相同方法训练的 Qwen-32B-Zero 效果比不上 SFT 后的效果。而R1-Zero 效果却接近 R1。 RL 还是适合基座模型能力较强(100B+模型)的范式,小模型用蒸馏学习就很好。 gpt4 程序员 软件开发 计算机
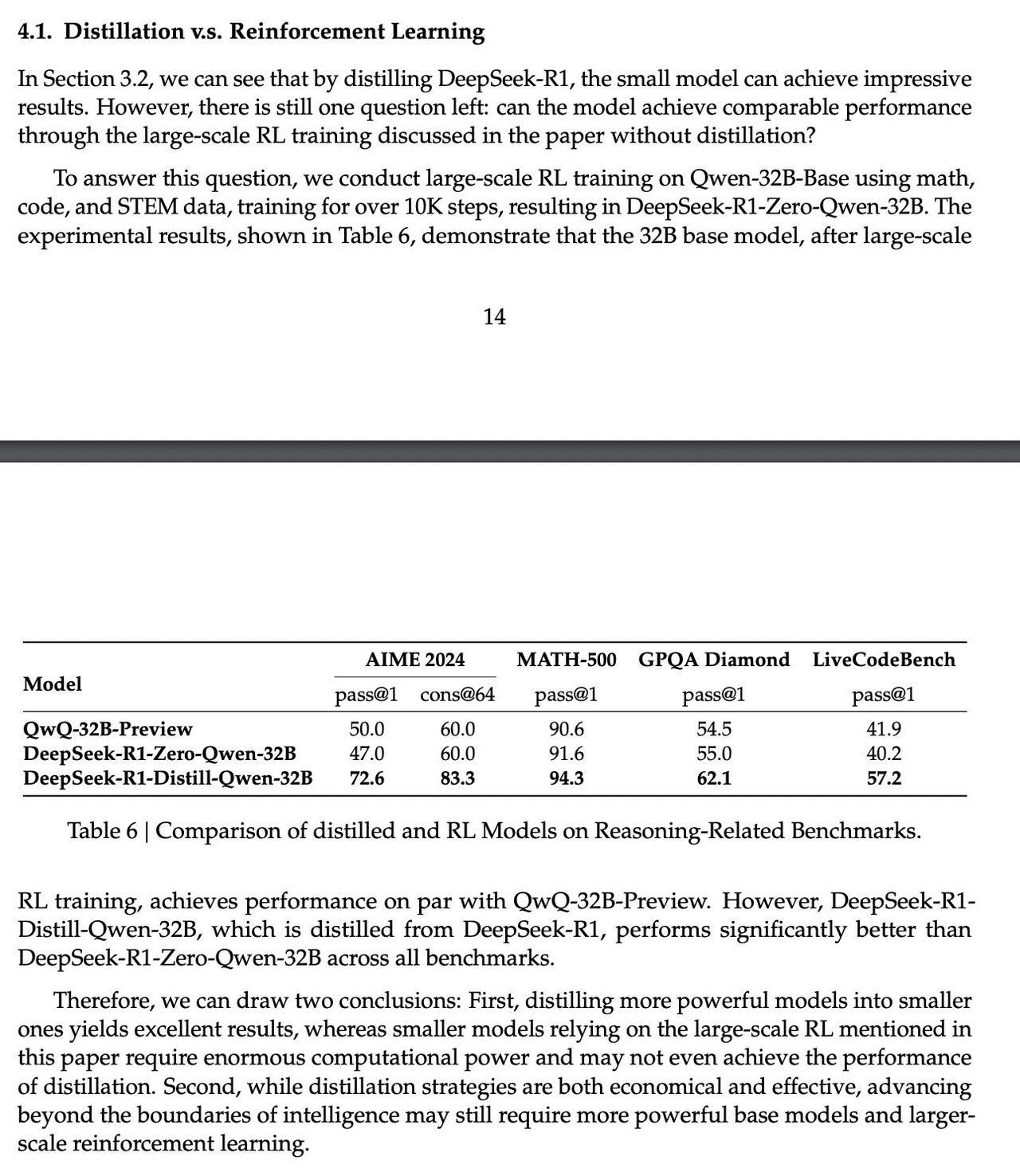
R1 的论文里也提到,使用R1-Zero 相同方法训练的 Qwen-32B-Zero 效果比不上 SFT 后的效果。而R1-Zero 效果却接近 R1。 RL 还是适合基座模型能力较强(100B+模型)的范式,小模型用蒸馏学习就很好。 gpt4 程序员 软件开发 计算机

作者最新文章
热门分类
科技TOP
科技最新文章