不蒸馏 R1 也能超越 DeepSeek,上海 AI Lab 用 RL 突破数学推理极限
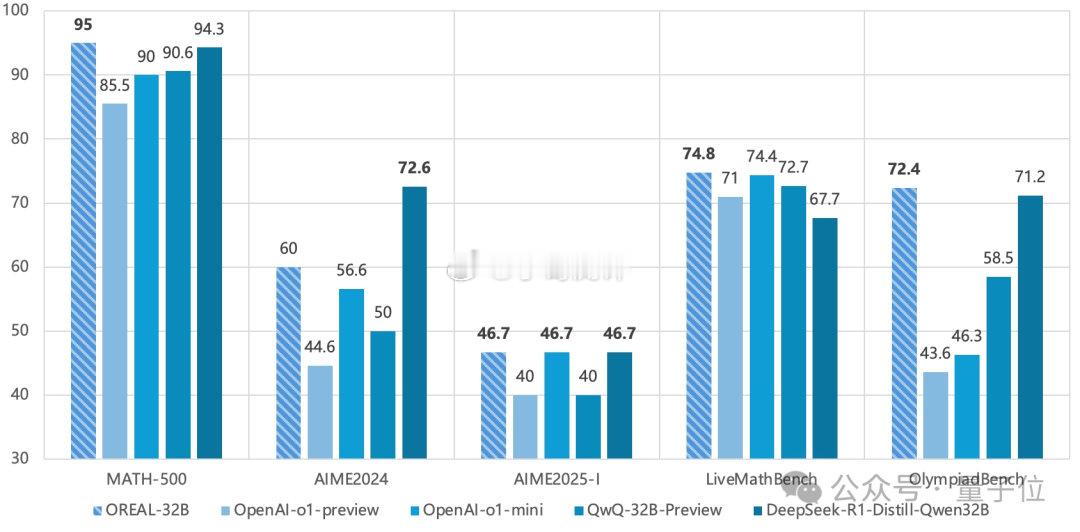
仅通过强化学习,就能超越 DeepSeek!上海 AI Lab 提出了基于结果奖励的强化学习新范式 ——从 Qwen2.5-32B-Base 模型出发,仅通过微调和基于结果反馈的强化学习,在不蒸馏超大模型如 DeepSeek-R1 的情况下,就能超越 DeepSeek-R1-Distill-Qwen32B 和 OpenAI-O1 系列的超强数学推理性能。
团队发现,当前大模型数学推理任务面临“三重门”困局:稀疏奖励困境:最终答案对错的二元反馈,使复杂推理的优化变得困难局部正确陷阱:
长思维链中部分正确步骤反而可能误导模型学习规模依赖魔咒:传统蒸馏方法迫使研究者陷入”参数规模军备竞赛”因此,研究团队重新审视了当前基于结果奖励的强化学习算法,经过严格的理论推导与证明,重新设计了一个新的结果奖励强化学习算法,并在这个过程中得出了三点重要结论:
对于正样本:在二元反馈环境下,通过最佳轨迹采样(BoN)的行为克隆即可学习最优策略对于负样本:需要使用奖励重塑来维护策略优化目标的一致性对于长序列:不同的序列部分对结果的贡献不同,因此需要更细粒度的奖励分配函数,这个函数可以通过结果奖励习得