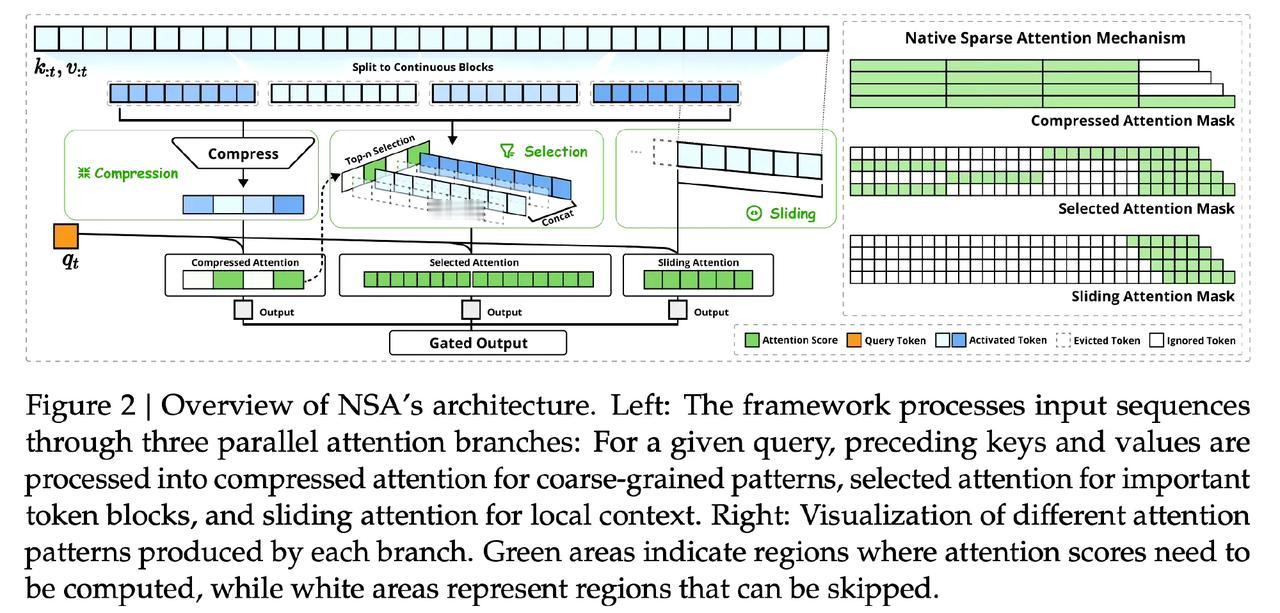
DeepSeek发布技术论文,这篇论文说简单点,就是在讲如何让计算机的注意力机制更快、更省资源。现在的AI模型,比如那些用Transformer架构的,处理长文本时计算量会爆炸,特别耗费时间和硬件资源。 deepseek这篇论文提出了一种叫“原生稀疏注意力”的方法。就好比我们读书时,不是每个字都细读,而是抓重点、挑重要的看。这个方法让模型只关注输入信息中关键的部分,而不是所有的细节,从而大大减少了计算量。 更厉害的是,这个稀疏注意力机制是和硬件高度匹配的,意思是在实际设备上运行起来效率更高,不需要对硬件做任何特殊设计。而且,这个方法可以直接训练,不需要复杂的预处理或者额外步骤,方便又实用。 总的来说,这项研究为大规模AI模型的加速和资源优化开辟了新道路,特别是在处理超长序列数据时效果显著。 这种技术的发展,可能会让高级AI模型在普通设备上运行成为可能。想象一下,将来我们的手机也能轻松跑起强大的AI应用,不再受限于计算资源,是不是很令人期待?