Meta SWE-RL:强化学习重塑代码AI,开源生态催生“数字软件工程师”
2025年2月26日,Meta AI实验室发布全新代码大模型Llama3-SWE-RL-70B,首次将强化学习(RL)与开源项目演化数据深度结合,在软件工程任务中实现里程碑式突破。 这一技术不仅以68.7%的准确率登顶SWEBench榜单,更以仅70B参数比肩GPT-4O,为AI辅助编程开辟了新范式。
---
技术革新:从“代码记忆”到“项目演化模拟”
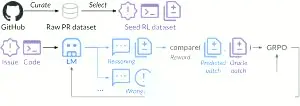
传统代码大模型依赖静态代码库训练,如同背诵教科书的学生,而SWE-RL的创新在于捕捉GitHub项目的动态生长轨迹。Meta利用数百万开源项目的版本历史,构建出包含代码修改、问题讨论、Bug修复全链条的“数字沙盘”。模型通过强化学习在此沙盘中反复试错:
- 当生成的代码补丁与开发者历史决策高度吻合时,系统给予正向奖励;
- 若出现逻辑冲突或低效实现,则触发惩罚机制并重新规划路径。
这种“开发者行为克隆”训练法,使模型习得了人类工程师的问题拆解思维与工程权衡意识。例如,面对“程序偶发崩溃”的模糊需求,模型能自动关联日志分析、单元测试补全等动作链,而非机械生成代码片段。
---
性能突破:小模型撼动行业格局
在权威测试集SWEBench中,Llama3-SWE-RL-70B以参数量不足GPT-4O一半的体量,实现与之相当的准确率(68.7% vs 69.1%),远超Deepseek-Coder-33B(61.2%)。其成功源于三大设计:
1. 动态数据聚焦:强化学习过滤了90%低频代码模式,专注高价值编程场景;
2. 上下文感知架构:通过注意力机制动态抓取项目全局依赖,避免“局部正确,全局翻车”;
3. 稀疏奖励优化:引入蒙特卡洛树搜索算法,破解长周期任务中的奖励延迟难题。
实测显示,该模型修复Python异常bug的准确率比同类模型提升42%,且生成的代码更符合项目规范。
---
产业重构:从工具到“数字同事”
SWE-RL的落地正改写软件开发流程:
- 问题响应自动化:可解析GitHub Issue,30秒内生成包含测试用例的PR草案,准确率较传统工具提升31%;
- 智能重构助手:在Java项目迁移中,自动保留87%的原有接口兼容性,降低技术债务;
- Bug逆向推理:通过异常日志反推错误根源,成功率接近中级工程师水平。
某开源社区测试显示,接入SWE-RL后,其功能迭代周期缩短40%,而代码审查工作量下降65%。
---
未来挑战:创造力与伦理的博弈
尽管SWE-RL在结构化任务上表现卓越,但在创造性设计(如算法优化)与跨系统协同(如微服务通信)领域仍存瓶颈。更深层的争议在于:当AI修复的代码涉及GPL协议冲突时,责任归属如何界定?Meta的开源策略虽加速技术民主化,但企业私有代码库的数据壁垒可能加剧AI编程能力的不平等。
这场变革已不可逆——SWE-RL标志着代码AI从“语法纠错器”正式升级为“项目参与者”。未来的开发者或许不再需要熬夜调试,而是化身“AI教练”,专注于更高维的创新与架构设计。当机器学会从历史中进化,软件工程的终极形态或将超越人类想象。