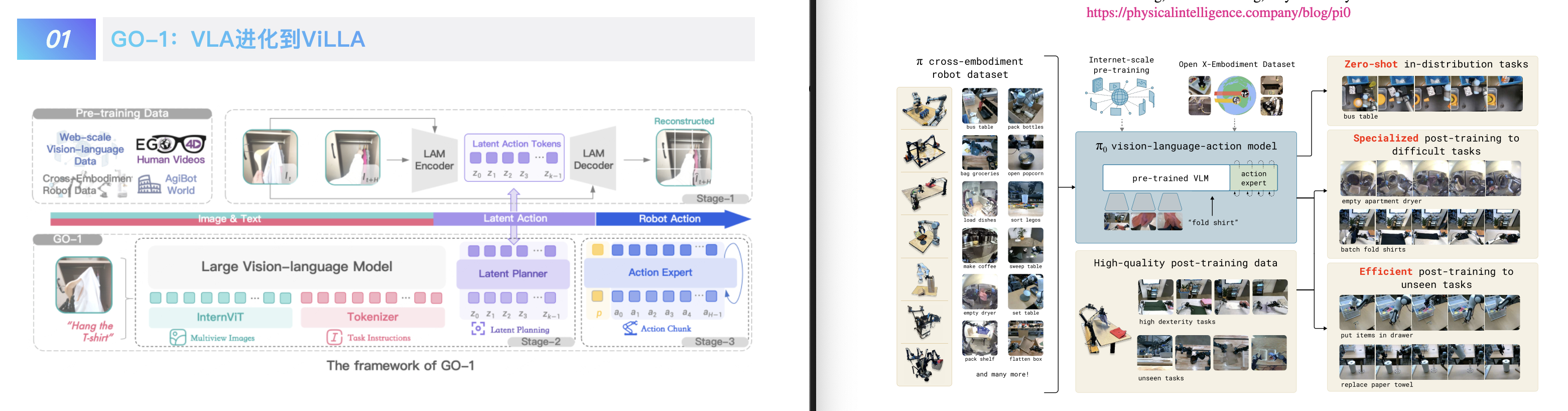
智元今天发布了通用具身模型 GenieOperator-1,去年 10 月一个美国的机器人创业公司 Physical Intelligence 也发布了一个通用机器人模型 π0。时间相差不远,索性放一起对比一下。
不得不说两家公司所做的两个模型在相当多的层面上都有异曲同工之妙。首先 GO-1 和 π0 本质上都是 VLA 视觉语言动作模型,或者更准确地说都是 VLM + 动作专家模型。也都基于语言和视觉的多模态输入来执行叠衣服、装东西等复杂任务。
在训练上,两家都利用了互联网上的视觉和语言数据,但同时也分别拿出了自家的高质量数据集(智元是去年开源的 AgiBot World 数据集,Physical Intelligence 是开源的 Open X Embodiment 数据集和 PI 自有的 8 个不同机器人任务的数据集),来实现模型跨任务的泛化能力。
但也有一些不同的做法。
比如 GO-1 的架构叫 ViLLA,Vision-Language-Latent-Action,多了一个 Latent 隐式规划器,这个隐式规划器的主要作用是通过预测和建模,从而让 GO-1 更好的基于互联网视频学习相关的动作知识。比如通过视频进行动作模仿。
而 π0 的一个亮点在于用了一种叫流匹配的 Diffusion 变体的模型来生成高达 50 Hz 的连续动作部分,那机器人看起来当然就自然灵活得多了。
总的来说,机器人领域的数据依然太少太少,智元的数据工厂已经扩大到号称 4000 平米的规格,可能是全球最大的机器人数据生产工厂了。但我跟 Grok-3 聊,它觉得这两个模型大致相当于 LLM 的 GPT-1 的阶段,为时尚早。
不过,数据的飞轮已经开始转动了。
智元机器人发布首个具身基座大模型