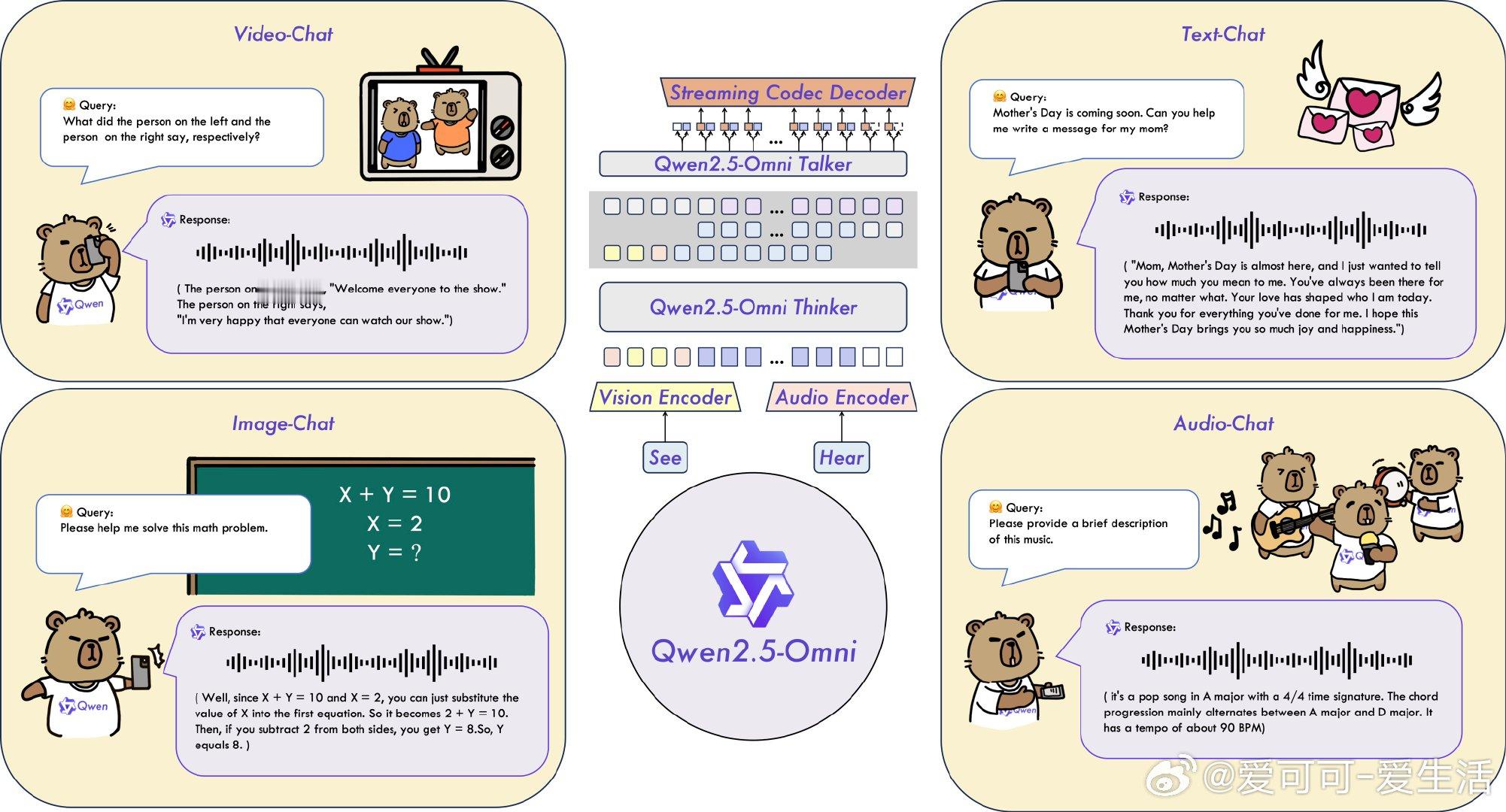
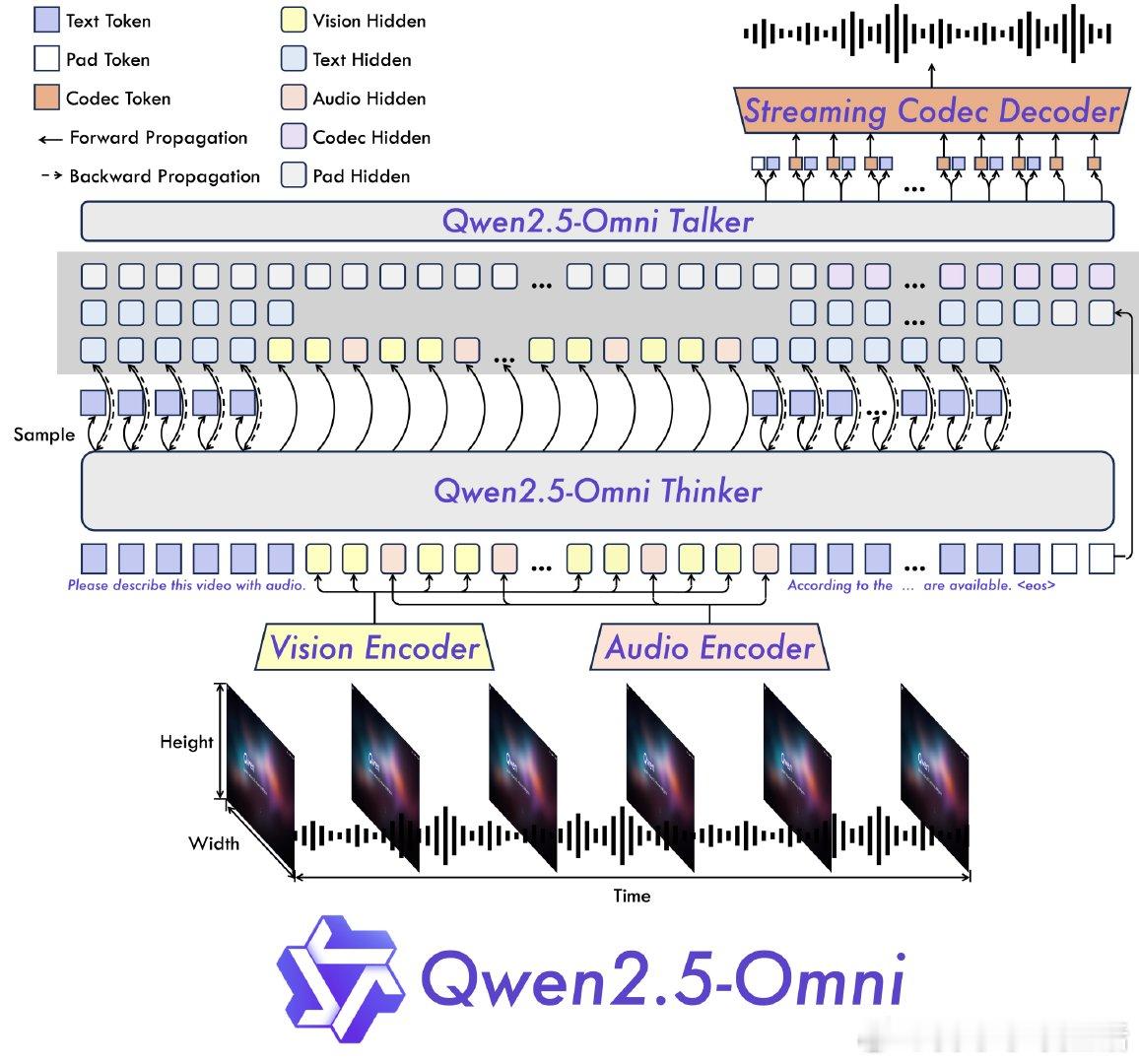
【[569星]Qwen2.5-Omni:阿里推出的Qwen系列旗舰多模态模型,能够一站式处理文本、图像、音频、视频等多种输入,并实时生成文本和自然语音响应。亮点:1. 提出创新的Thinker-Talker架构和TMRoPE(时间对齐多模态RoPE)位置嵌入,同步处理视频与音频输入;2. 在多模态任务中表现卓越,例如在OmniBench任务中,性能超越多个开源和闭源模型,平均准确率高达56.13%;3. 在语音生成方面表现自然且鲁棒性强,例如在Seed-tts-eval主观自然度评估中表现优异】
'Qwen2.5-Omni is an end-to-end multimodal model by Qwen team at Alibaba Cloud, capable of understanding text, audio, vision, video, and performing real-time speech generation.'
GitHub: github.com/QwenLM/Qwen2.5-Omni
多模态模型 实时语音生成 多模态感知 AI创造营