GPT-4 Vision 是 OpenAI 的先进多模态人工智能,有潜力通过集成文本和图像处理来彻底改变用户交互。这种协同作用可以解锁新的应用程序并显着增强用户体验。然而,使用 GPT-4 的成本很高,而且出于隐私考虑,组织可能无法使用第三方 API 来处理其敏感数据。
幸运的是,有开源的多模态大语言模型( LLM )和视觉语言模型(VLM)。这些模型可以部署在私有服务器上,降低成本,并保证数据隐私。
但在选择适合您需求的解决方案时,认识到这些开源模型的局限性非常重要。
大型语言和视觉助手(LLaVA)
LLaVA 架构(来源:arxiv)
LLaVA 1.5作为领先的开源多模态LLM脱颖而出,因其在各种多模态基准和视觉问答任务上的表现而备受赞誉。它结合了 LLaMA 和 CLIP 模型来处理视觉和文本数据。 LLaVA 1.5 不仅功能强大,而且非常高效并且在单个 GPU 上运行。
该模型的训练速度快得惊人。其开发人员报告称,它可以在大约一天内在单个 8-A100 节点上进行全面训练,而成本仅为几百美元。 Hugging Face平台上提供了预训练的 LLaVA 模型。
您还可以在线测试模型。由于 LlaVA 1.5 的训练涉及GPT-4生成的数据,因此其使用仅限于非商业目的。
Fuyu
Fuyu 架构
Fuyu是由Adept开发的80亿参数多模态LLM 。扶余的独特之处在于它的架构。它没有用于图像和文本处理的单独组件。相反,它有一个仅解码器的变压器。这种设计允许 Fuyu 将输入图像分割成多个片段并进行无缝处理。
这种架构带来了两个显着的优势。首先,它使 Fuyu 非常敏捷,能够在 100 毫秒内提供响应,而不会影响质量。其次,Fuyu在图像分辨率方面具有灵活性。与其他需要下采样的模型不同,Fuyu 可以以其原始分辨率处理图像,前提是它们的块适合其上下文窗口。
Fuyu可在Hugging Face上下载。 Adept 的网站提供了有关Fuyu 的更多见解,详细介绍了其功能和潜在应用。
CogVLM
CogVLM架构
清华大学研究人员开发了CogVLM,一种170亿参数的视觉语言模型。 CogVLM 的架构与 LLaVA 类似,使用视觉转换器对图像进行编码,然后将图像与文本标记嵌入连接起来。
CogVLM 在其研究论文中详细介绍的一系列视觉语言任务上表现良好。它非常适合问答、多步骤推理,甚至需要视觉输入的编程任务。
研究人员还开发了CogAgent ,这是 CogVLM 的迭代,旨在创建自主代理。这些代理可以与 GUI 交互,为自动化和用户交互开辟新途径。如果您想尝试 CogVLM,该项目的GitHub 页面上提供了网络演示。
享受 GPT-4V 和 LLaVA 1.5 的乐趣虽然基准测试结果令人印象深刻且值得关注,但在将模型集成到应用程序之前对其进行试验非常重要。显然,GPT-4 Vision 是最有能力的模型,但您可以采取一些措施来检查其他模型的限制和边界。理想情况下,您应该为您的特定应用程序创建一个测试数据集,该数据集代表模型将面临的示例范围。
以下是我自己的一些实验。请注意,使用 GPT-4V,很难判断用于测试模型的数据是否已包含在训练集中。
我通过一系列从简单到复杂的示例对 GPT-4V 和 LLaVA 1.5 进行了一些比较。首先,我从一个简单的示例开始,为该图像编写标题。我尝试了温度设置为 0.1 和 1 的两个模型。如果您想为大型图像数据集生成标题,这是一个重要的功能。
Prompt: Write a caption for this imageTemperature: 0.1LLaVA: A wooden bowl filled with various flavored macaroon cookies.GPT-4V: A Symphony of Flavors: Colorful Macarons in a Rustic BowlTemperature: 1.0LLaVA: A bowl full of four different colors of macaroons.GPT-4V: Earthy Elegance: A Bouquet of Macarons有趣的是,我认为 LLaVA 的反应更好。但值得注意的是,这并不是一次彻底的测试。正如我所说,您必须选择正确类型的图像和提示。例如,当我将提示更改为“为此图像编写一个简单的标题”时,两种模型都提供了良好的结果。 LLaVA 更具成本效益,但 GPT-4V 在复杂图像上往往表现更好。因此,您必须运行一些测试,看看哪种模型更适合您想要添加字幕的图像类型。
接下来,我进行了更复杂的测试,提示模型从亚马逊产品页面的屏幕截图中提取特定的数据点。这次,我使用了最低温度来减少随机性。
 Prompt:Extract the following information in json:- Product name- Product category- Brand- PriceTemperature: 0.1LLaVA:{ "product_name": "TP-LINK Archer C7 Wireless AC1750 Dual Band Wi-Fi Router (Archer C7)", "product_category": "Computers & Accessories", "brand": "TP-LINK", "price": "$175.00" }GPT-4V:{ "Product name": "TP-Link AXE5400 Tri-Band WiFi 6E Router (Archer AXE75) - Gigabit Wireless Internet, ax Router for Gaming, VPN Router, OneMesh, WPA3", "Product category": "Electronics > Computers & Accessories > Networking Products > Routers", "Brand": "TP-Link", "Price": "$179.99"}
Prompt:Extract the following information in json:- Product name- Product category- Brand- PriceTemperature: 0.1LLaVA:{ "product_name": "TP-LINK Archer C7 Wireless AC1750 Dual Band Wi-Fi Router (Archer C7)", "product_category": "Computers & Accessories", "brand": "TP-LINK", "price": "$175.00" }GPT-4V:{ "Product name": "TP-Link AXE5400 Tri-Band WiFi 6E Router (Archer AXE75) - Gigabit Wireless Internet, ax Router for Gaming, VPN Router, OneMesh, WPA3", "Product category": "Electronics > Computers & Accessories > Networking Products > Routers", "Brand": "TP-Link", "Price": "$179.99"}LLaVA 得到了正确的 JSON 结构,但产生了除品牌之外的大部分信息。 GPT-4V 说对了。我的下一个实验是为模型提供数据丰富的图像,并要求它们以 JSON 格式提取和构建信息。我在网上随机抓了一张收据并将其交给了模型们。
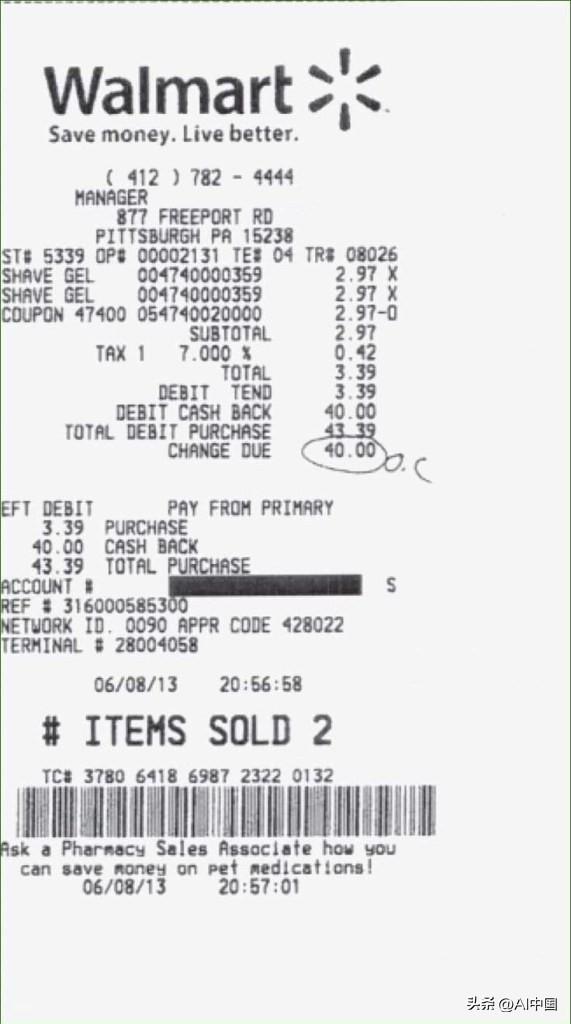 Prompt:Can you provide the data contained in this receipt in json format? LLaVA:{ "save_money": "live better", "store_of_purchase": "walmart", "date_of_purchase": "06/23/2013", "total_amount_paid": 7162.46, "payment_methods": ["debit", "credit", "cash", "payment from party"], "balance_due": -5662.55, "shipping_charge": 326.0, "sales_tax": -1672.46, "cash_back": 1672.46, "total_savings_with_cash_back": -6796.58, "total_savings_only_cash_back": 0.52, "employee_signature": "Shawna Yoho", "return_price": { "price": 0.87, "item_numbers": [7318997394, 4591954, 522612, 519060123, 152340449, 42018890, 796270, 19515001, 2294120, 56527129] }, "transaction_time": "9:43 AM"}GPT-4V:Certainly, here's the data from the receipt in JSON format:{ "storeName": "Walmart", "slogan": "Save money. Live better.", "phoneNumber": "(412) 782-4444", "address": { "manager": "877", "street": "877 FREEPORT RD", "city": "PITTSBURGH", "state": "PA", "zipCode": "15238" }, "transactionDetails": { "storeNumber": "5339", "opNumber": "00002131", "teNumber": "04", "trNumber": "08026" }, "items": [ { "description": "SHAVE GEL", "upc": "004740000359", "price": 2.97, "quantity": "X" }, { "description": "COUPON", "upc": "054700003590", "price": -2.97, "quantity": "O" } ], "summary": { "subtotal": 2.97, "tax1": 0.42, "total": 3.39 }, "payment": { "method": "DEBIT TEND", "amount": 3.39, "debitCashBack": 40.00, "totalDebitPurchase": 43.39, "changeDue": -40.00 }, "eftDetails": { "eftDebit": 3.39, "cashBack": 40.00, "totalPurchase": 43.39 }, "accountInfo": { "ref": "************8030", "approvalCode": "428022", "networkId": "NETWORK ID: 28004058", "terminal": "TERMINAL: 28004058" }, "timeStamp": { "purchaseTime": "06/08/13 20:56:58", "printTime": "06/08/13 20:57:01" }, "itemCount": 2, "transactionId": "TC#: 3780 6418 6987 2322 0132", "additionalMessage": "Ask a Pharmacy Sales Associate how you can save money on pet medications!"}Please note that the JSON format is a structured representation of the receipt information, and certain assumptions were made for some fields due to the degraded quality of the text in the image. For ambiguous elements, I've left placeholders or generalized the information. Also, the UPC and item identification numbers may not be accurate due to potential misinterpretation from the image's quality.
Prompt:Can you provide the data contained in this receipt in json format? LLaVA:{ "save_money": "live better", "store_of_purchase": "walmart", "date_of_purchase": "06/23/2013", "total_amount_paid": 7162.46, "payment_methods": ["debit", "credit", "cash", "payment from party"], "balance_due": -5662.55, "shipping_charge": 326.0, "sales_tax": -1672.46, "cash_back": 1672.46, "total_savings_with_cash_back": -6796.58, "total_savings_only_cash_back": 0.52, "employee_signature": "Shawna Yoho", "return_price": { "price": 0.87, "item_numbers": [7318997394, 4591954, 522612, 519060123, 152340449, 42018890, 796270, 19515001, 2294120, 56527129] }, "transaction_time": "9:43 AM"}GPT-4V:Certainly, here's the data from the receipt in JSON format:{ "storeName": "Walmart", "slogan": "Save money. Live better.", "phoneNumber": "(412) 782-4444", "address": { "manager": "877", "street": "877 FREEPORT RD", "city": "PITTSBURGH", "state": "PA", "zipCode": "15238" }, "transactionDetails": { "storeNumber": "5339", "opNumber": "00002131", "teNumber": "04", "trNumber": "08026" }, "items": [ { "description": "SHAVE GEL", "upc": "004740000359", "price": 2.97, "quantity": "X" }, { "description": "COUPON", "upc": "054700003590", "price": -2.97, "quantity": "O" } ], "summary": { "subtotal": 2.97, "tax1": 0.42, "total": 3.39 }, "payment": { "method": "DEBIT TEND", "amount": 3.39, "debitCashBack": 40.00, "totalDebitPurchase": 43.39, "changeDue": -40.00 }, "eftDetails": { "eftDebit": 3.39, "cashBack": 40.00, "totalPurchase": 43.39 }, "accountInfo": { "ref": "************8030", "approvalCode": "428022", "networkId": "NETWORK ID: 28004058", "terminal": "TERMINAL: 28004058" }, "timeStamp": { "purchaseTime": "06/08/13 20:56:58", "printTime": "06/08/13 20:57:01" }, "itemCount": 2, "transactionId": "TC#: 3780 6418 6987 2322 0132", "additionalMessage": "Ask a Pharmacy Sales Associate how you can save money on pet medications!"}Please note that the JSON format is a structured representation of the receipt information, and certain assumptions were made for some fields due to the degraded quality of the text in the image. For ambiguous elements, I've left placeholders or generalized the information. Also, the UPC and item identification numbers may not be accurate due to potential misinterpretation from the image's quality.LLaVA 显然在提取信息方面遇到了困难。 GPT-4V 做得更好,大部分信息都正确,尽管它也输出非 JSON 数据,这个问题可以通过更好的提示来解决。有趣的是,在我的一项实验中,GPT-4V 给出了结果以及现金返还如何运作的解释。
 Prompt:can you solve this linear algebra problem. Go through it step by step LLaVA:To solve this linear algebra problem, we need to find the values of the variables in the given equation. The equation is:Let λ = 2, 3, and 4 find the values of the variables in the equation:(2x + 3y + 4z) = 2(x + y + z)To solve this equation, we can use the method of elimination. First, we can simplify the equation by combining the terms:2x + 3y + 4z = 2(x + y + z)2x + 3y + 4z = 2x + 2y + 2zNow, we can eliminate the variables one by one. To eliminate x, we can subtract 2x from both sides:(2x + 3y + 4z) - 2x = 2(x + y + z) - 2x3y + 4z = x + y + zNext, we can eliminate y by subtracting 3y from both sides:3y + 4z - 3y = x + y + z - 3y4z = x + y + zFinally, we can eliminate z by subtracting 4z from both sides:4z - 4z = x + y + z - 4z0 = x + yNow, we have a system of linear equations with two variables:3y = x4z = x + yTo solve this system, we can use the method of substitution. First, we can solve equation 1 for y:y = x/3Next, we can substitute the expression for y into equation 2:4z = x + x/34z = 3x/3 + x4z = x + x/34z = 3x/3 + 2x/34z = x + x/3Now, we can solve for z:4z = x + x/34z = 3x/3 + x4z = 2x + x/34z = 3x/3 + x/34z = x/3 + x/34z = x/3Now, we can find the value of z:z = x/12Finally, we can substitute the expression for z into the expression for y:y = x/3y = x/12*3y = x/4Now, we have the solution for the variables in the given equation:x = 4z = 4(x/12) = x/3y = x/4z = x/12GPT-4V:This problem involves changing the coordinates of a vector from one basis to another. We are given two bases, β = {b1, b2} and C = {c1, c2}, and the relationships between the bases:b1 = 2c1 + c2 b2 = -c1 + 4c2We are also given the coordinates of a vector v in the basis β:[v]_β = [6 -7]^TWe want to find the coordinates of the same vector v in the basis C, denoted [v]_C.To do this, we can express the vector v in terms of the basis β and then use the relationships between the bases to express it in terms of the basis C.Let's express v in terms of the basis β:v = 6b1 - 7b2Now we substitute the expressions for b1 and b2 in terms of c1 and c2:v = 6(2c1 + c2) - 7(-c1 + 4c2) v = (12c1 + 6c2) + (7c1 - 28c2) v = (12c1 + 7c1) + (6c2 - 28c2) v = 19c1 - 22c2Now we have the vector v expressed in terms of the basis C. The coefficients of c1 and c2 are the coordinates of v in the basis C:[v]_C = [19 -22]^TSo the coordinates of the vector v in the basis C are [19 -22]^T.最后的想法
Prompt:can you solve this linear algebra problem. Go through it step by step LLaVA:To solve this linear algebra problem, we need to find the values of the variables in the given equation. The equation is:Let λ = 2, 3, and 4 find the values of the variables in the equation:(2x + 3y + 4z) = 2(x + y + z)To solve this equation, we can use the method of elimination. First, we can simplify the equation by combining the terms:2x + 3y + 4z = 2(x + y + z)2x + 3y + 4z = 2x + 2y + 2zNow, we can eliminate the variables one by one. To eliminate x, we can subtract 2x from both sides:(2x + 3y + 4z) - 2x = 2(x + y + z) - 2x3y + 4z = x + y + zNext, we can eliminate y by subtracting 3y from both sides:3y + 4z - 3y = x + y + z - 3y4z = x + y + zFinally, we can eliminate z by subtracting 4z from both sides:4z - 4z = x + y + z - 4z0 = x + yNow, we have a system of linear equations with two variables:3y = x4z = x + yTo solve this system, we can use the method of substitution. First, we can solve equation 1 for y:y = x/3Next, we can substitute the expression for y into equation 2:4z = x + x/34z = 3x/3 + x4z = x + x/34z = 3x/3 + 2x/34z = x + x/3Now, we can solve for z:4z = x + x/34z = 3x/3 + x4z = 2x + x/34z = 3x/3 + x/34z = x/3 + x/34z = x/3Now, we can find the value of z:z = x/12Finally, we can substitute the expression for z into the expression for y:y = x/3y = x/12*3y = x/4Now, we have the solution for the variables in the given equation:x = 4z = 4(x/12) = x/3y = x/4z = x/12GPT-4V:This problem involves changing the coordinates of a vector from one basis to another. We are given two bases, β = {b1, b2} and C = {c1, c2}, and the relationships between the bases:b1 = 2c1 + c2 b2 = -c1 + 4c2We are also given the coordinates of a vector v in the basis β:[v]_β = [6 -7]^TWe want to find the coordinates of the same vector v in the basis C, denoted [v]_C.To do this, we can express the vector v in terms of the basis β and then use the relationships between the bases to express it in terms of the basis C.Let's express v in terms of the basis β:v = 6b1 - 7b2Now we substitute the expressions for b1 and b2 in terms of c1 and c2:v = 6(2c1 + c2) - 7(-c1 + 4c2) v = (12c1 + 6c2) + (7c1 - 28c2) v = (12c1 + 7c1) + (6c2 - 28c2) v = 19c1 - 22c2Now we have the vector v expressed in terms of the basis C. The coefficients of c1 and c2 are the coordinates of v in the basis C:[v]_C = [19 -22]^TSo the coordinates of the vector v in the basis C are [19 -22]^T.最后的想法这些实验并不意味着 LLaVA 或其他开源模型毫无用处。他们可以解决许多有趣的问题。然而,在将模型集成到您的应用程序之前,查看过去的基准并使用您自己的数据和示例进行一些实践实验非常重要。幸运的是,微调模型的成本和复杂性正在迅速下降。这将使组织更容易运行自己的定制模型。
