prometheus 不同告警分发到不同团队 part2
4.rules/dev/node-exporter.yaml配置
关键点
a.有 team 参数,并区分dev 团队
b.指标查询中,带有 {cluster="sz-dev"} ,dev所属的标签,跟target 相同
groups:- name: node-exporter rules:##内存监控 - alert: memory-high expr: | 100*((node_memory_MemTotal_bytes{cluster="sz-dev"}-node_memory_MemFree_bytes{cluster="sz-dev"}-node_memory_Buffers_bytes{cluster="sz-dev"}-node_memory_Cached_bytes{cluster="sz-dev"})/node_memory_MemTotal_bytes{cluster="sz-dev"}) > 5 for: 1m labels: severity: warning team: meta-dev #team分组 Alertmanager对应值分组告警 annotations: description: 节点{{ $labels.instance }} 内存使用率为 {{ printf "%.2f" $value}}% 超过阈值 85% summary: "Node memory utilization is over threshold"5.rules/qa/node-exporter.yaml配置
关键点
a.有 team 参数,并区分qa 团队
b.指标查询中,带有 {cluster="sz-qa"} ,qa所属的标签,跟target 相同
groups:- name: node-exporter rules:##CPU - alert: cpu-high expr: | 100 - avg(irate(node_cpu_seconds_total{cluster="sz-qa",mode="idle"}[5m])) by (instance) * 100 > 5 for: 1m labels: severity: critical team: meta-qa #team分组 Alertmanager对应值分组告警 annotations: description: 节点{{ $labels.instance }} cpu {{ $labels.cpu }} 使用率为{{printf "%.2f" $value }}% 超过阈值 95% summary: "Node cpu utilization is over threshold"6.target 目标标签
targets/node-exporter/dev.yaml
cluster 标签及value ,在rules 查询时使用,同时在alertmanger中做分组识别
- labels: cluster: sz-dev env: dev-10-14 targets: - '192.168.10.14:9100'targets/node-exporter/qa.yaml
cluster 标签及value ,在rules 查询时使用,同时在alertmanger中做分组识别
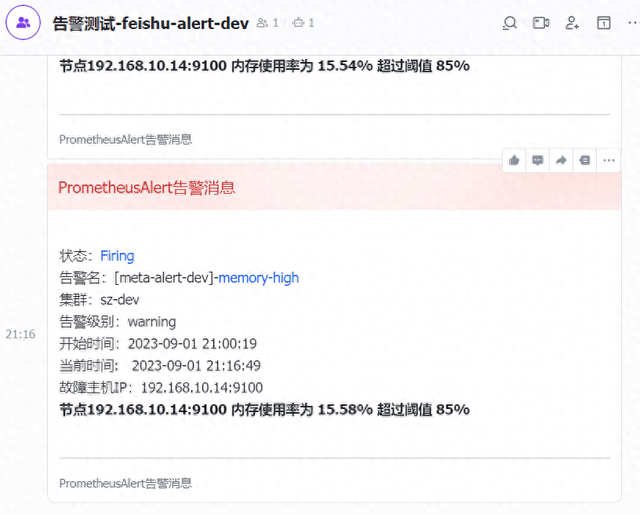
- labels: cluster: sz-qa env: qa-102-238 targets: - '192.168.102.238:9100'7.告警截图展示
dev团队对应team的meta-dev标签,集群sz-dev
qa团队对应team的meta-qa标签,集群sz-qa (cpu采集综合CPU,未显示cluster标签)

运维团队只涉及服务级别,或在发给不同团队时,抄送一份给运维

