AI 落地不分大小,重点是一定要有真实的场景。
我想开发一款 AI 文字纠错的工具,是因为我公司的小编,每天都要在官网、公众号等多个渠道发文章,发文数量挺大,国内国外都有,还用到了3-4门语言。 所以错别字和语法检查,属于我公司的刚需,我决定做一款工具来帮助小编。
说干就干,首选通过 Dify 搭建,这是迄今为止我用过最好的 AI 应用开发平台,通过拖拉拽的方式搭建 AI 流程,简单直观,功能体验绝对属于头部,并且开源免费。
Dify官网:https://dify.ai/zh
如果你有一些技术基础,完全可以在本地部署一套自己的 Dify,推荐用 Docker 方式搭建,如果官方有升级,几分钟就能完成升级。不想自己折腾也没事,完全可以用 Dify 官方的云版本,免费账号有 200 条 OpenAI 等大模型调用,体验一下完全够了,实际用起来了可以再买会员。
关于 Dify 就介绍这么多,下面假设你已经有了 Dify 账号,开始进入正式搭建环节。
AI 如何完成错别字和语法检查工作AI 仅靠 prompt 提示词,就能很好地纠错。我首先想到的是,可以借鉴吴恩达教授翻译 Agent 的思路,即先让 AI 检查第一遍,接着反思第一遍的结果,最后根据反思建议输出最终的结果。
最终流程跟这个差不多,但我发现,如果整个流程都放在一步完成,反思基本没啥效果,可能 95% 的时候都跟没有一样。哪怕有时候反思到第一遍存在问题,最终结果也大概率没有真的改正。
最终的方案是,分成两个独立的步骤:
让 AI 进行第一遍检查,输出错别字、语法或标点等有问题的记录;再让 AI对第一遍的输出结果进行二次确认。把可有可无的错误去除,保证只输出值得关注的错误。AI 错别字和语法检查工作流相比聊天或 Agent,我认为工作流(workflow)更合适,Dify 完整的工作流如下:

错别字和语法检查工作流
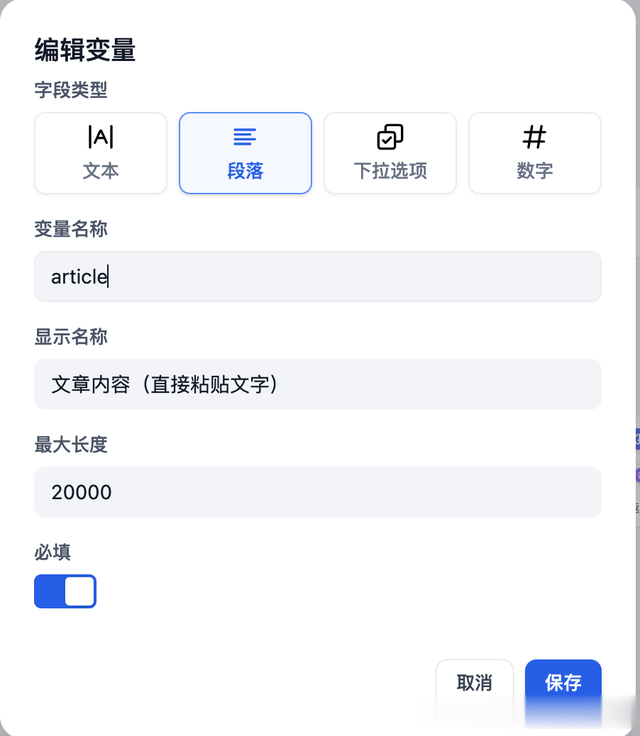
开始:配置多行文本框变量,用于小编输入文章内容。
获取日期:通过 Python 代码获取当前日期,放到 prompt 提示词中。如果文章内容包括时间,这可以避免一些 AI 因时间造成的误判(如果不给,AI 对时间的概念停留在训练数据的截止日期)。
from datetime import datetimedef main() -> dict: from datetime import datetime # 获取当前时间 current_time = datetime.now() return { "current_date": current_time.strftime("%Y-%m-%d"), }AI 检查错别字和语法:在确定 prompt 提示词之前,需要反复测试和调整。
我的方法是:先自己写清楚任务和要求,越细越好;把自己写好的草稿给 Claude 的提示词生成器(Generate a Prompt),这是最好的提示词生成器,效果炸裂;复制 Prompt 到你将调用的大模型后台测试,发现问题,迭代改进直到满意为止。
You are acting as Grammarly, a professional proofreading and grammar checking tool. Your task is to check the spelling and grammar of an article, identifying and suggesting corrections for typos, grammatical errors (such as verb tense errors, subject-verb disagreements, inappropriate sentence structures, etc.). You should consider the structure and context of entire sentences, not just individual words or phrases. Your response (Error type, Explanation etc.) must be written in the same language as the article content.Now, carefully read through the article and perform a paragraph-by-paragraph check. Identify any errors you find and suggest corrections. List each error you've identified along with its correction. For each error, provide:1. The original text containing the error2. The type of error (e.g., spelling, grammar,punctuation)3. An explanation of why it's incorrect4. The suggested correctionOutput the final result in JSON format, structured as an array (list). Each element (object) in the array should contain the following fields:{ "errors:[{ "Original": "[Insert original text]", "Error type": "[Specify error type in Chinese]", "Explanation": "[Explain in Chinese why it is incorrect], Correction: "[Provide corrected text]"}]}IMPORTANT:- The article given to you is in plain text format. Disregard any checks related to text formatting, layout styles, and font colors.- Do not perform checks regarding whether spaces should be kept between Chinese characters, English words, or numbers.- You should take into account the style and conventions of the language corresponding to the original text's country when performing spelling and grammar checks.- Your focus should be on significant errors, while disregarding minor, inconsequential issues.- Texts containing nonsensical, meaningless, or unintelligible content are not acceptable in their current form and should be considered genuine errors.Remember to consider the context and ensure your suggestions maintain the original meaning and tone of the article.Current date: {{current_date}}Here is the article you need to check:<article>{{article}}</article>代码:过滤错误结果。这一步骤起两个作用,一是把错误结果从字符串转成列表(方便计算条数),二是通过程序判断,是否原文和改正一模一样?如果是,说明本条判断有误,去掉它(我测试小概率会出现这种情况)。
import jsondef main(result: str) -> dict: result = json.loads(result) errors = result.get("errors", []) corrected_errors = [] # 如果 errors 非空并且是列表 if errors and isinstance(errors, list): for error in errors: original = error.get("Original") correction = error.get("Correction") # 比较 Original 和 Correction 是否一样 if original != correction: corrected_errors.append(error) # 排序规则:如果 "Error type" 包含 "标点符号" 或 "格式",则排到最后 corrected_errors.sort(key=lambda x: ("标点符号" in x.get("Error type", "")) or ("格式" in x.get("Error type", ""))) return { "errors": corrected_errors }分支:判断是否有错误。如果没有任何错误,恭喜小编,流程结束。如果有,则进入第二个流程。
LLM:二次校对。即对第一步输出的错误结果本身,让 AI 判断是否存在可有可无的错误,甚至是根本没有错误,对这些记录进行标记。
You are tasked with reviewing a list of potential errors in a text and identifying which ones are false errors. False errors are corrections that are unnecessary, overly pedantic, or actually incorrect. Your goal is to analyze each error and determine if it's a genuine error or a false one.For each error in the list:1. Carefully read the original text, the error type, the explanation, and the correction.2. Consider whether the proposed correction is necessary, improves clarity, or adheres to formal writing standards.3. Determine if the correction might introduce new errors or change the meaning of the text.4. Assess whether the error is overly pedantic or if the original text is acceptable in its current form.Identify false errors based on the following criteria:- The original text is clear and grammatically correct.- The proposed correction doesn't significantly improve the text.- The correction introduces unnecessary formality or complexity.- The explanation misinterprets the context or intent of the original text.- The correction changes the meaning of the original text.- Texts containing nonsensical, meaningless, or unintelligible content are not acceptable in their current form and should be considered genuine errors.- The important formatting issue is a real mistake.After analyzing all errors, identify the false errors. A false error is one where the original text is acceptable or preferable to the correction.Your response only outputs the false error number without anything else. The format is as follows:<false_errors>List the numbers (starting from 1) of the errors you've identified as false errors, separated by English commas.</false_errors>Remember, your task is to identify false errors, not to correct genuine errors. Focus on finding corrections that are unnecessary or potentially problematic.Current date: {{current_date#}}代码:过滤二次校对结果。根据二次校对结论,从第一遍的检查结果中,去掉那些可有可无的错误,只保留真正值得关注的错误。
避免因 AI 说一些不痛不痒的问题,价值感不大,导致小编不想用。
import redef main(false_errors: str, errors_list: list) -> dict: # 使用正则表达式提取 <false_errors> 标签中的数字 numbers = false_errors.replace("<false_errors>","").replace("</false_errors>","").replace("\n","").strip() # 将字符串中的数字提取并转换为列表形式 if numbers: # 首先尝试用逗号分割,如果没有逗号则用空格分割 split_numbers = numbers.split(',') if ',' in numbers else numbers.split() # 将非空的字符串转换为整数列表,并将序号减去 1 false_error_indices = [int(x.strip()) - 1 for x in split_numbers if x.strip()] else: false_error_indices = [] print(false_error_indices) # 去除错误列表中的 false errors 项目 filtered_errors_list = [ item for i, item in enumerate(errors_list) if i not in false_error_indices and i < len(errors_list) ] return { "result": filtered_errors_list, }分支:判断是否有错误。如果没有任何错误,恭喜小编,流程结束。如果有错误则继续。
代码:标记修正结果。为了让小编一眼知道哪里做了修改,最好对原文和改正进行差异比较,原文被删除的文字画上删除线,新增的则加粗(配合颜色最好,但 Dify 目前只支持 markdown格式,没办法标记颜色)。
import difflibimport re# 定义中英文标点符号PUNCTUATIONS = ',。!?、;:“”‘’()《》〈〉[]{}<>.,!?;:"\'()<>'# 分词函数:将文本分割为英文单词和非英文字符def tokenize(text): # 使用正则表达式将英文单词和非英文字符分开 tokens = re.findall(r'[A-Za-z]+|\s+|[^A-Za-z\s]', text) return tokens# 比较并突出显示不同部分,英文按单词,中文和日文按字符,并合并相邻相同类型的差异def highlight_differences(original, correction): original_tokens = tokenize(original) correction_tokens = tokenize(correction) matcher = difflib.SequenceMatcher(None, original_tokens, correction_tokens) result = [] for tag, i1, i2, j1, j2 in matcher.get_opcodes(): if tag == 'equal': # 无差异部分,直接添加 result.append(''.join(original_tokens[i1:i2])) elif tag == 'replace': # 替换操作,标记删除和新增部分 deleted = ''.join(original_tokens[i1:i2]) inserted = ''.join(correction_tokens[j1:j2]) # 确保标记不包括前后的空格 newitem = f"{' ' if deleted.startswith(' ') else ''}~~{deleted.strip()}~~ **{inserted.strip()}**{' ' if inserted.endswith(' ') else ''}" if deleted.strip() and deleted.strip()[0] in PUNCTUATIONS: if result and not result[-1].endswith(' '): newitem = f" {newitem}" result.append(newitem) elif tag == 'delete': # 删除操作,标记删除部分 deleted = ''.join(original_tokens[i1:i2]) newitem = f"{' ' if deleted.startswith(' ') else ''}~~{deleted.strip()}~~{' ' if deleted.endswith(' ') else ''}" if deleted.strip() and deleted.strip()[0] in PUNCTUATIONS: if result and not result[-1].endswith(' '): newitem = f" {newitem}" result.append(newitem) elif tag == 'insert': # 插入操作,标记新增部分 inserted = ''.join(correction_tokens[j1:j2]) newitem = f"{' ' if inserted.startswith(' ') else ''}**{inserted.strip()}**{' ' if inserted.endswith(' ') else ''}" if inserted.strip() and inserted.strip()[0] in PUNCTUATIONS: if result and not result[-1].endswith(' '): newitem = f" {newitem}" result.append(newitem) highlighted = ''.join(result) # 替换连续四个相同符号(~~~~ 或 ****)为空字符串 highlighted = re.sub(r'(~~~~|\*\*\*\*)', '', highlighted) return highlighted# 修改为返回字符串def display_corrections(data): results = [] for i, entry in enumerate(data, 1): # 使用 enumerate 添加序号 # 每个条目格式化为字符串 result_item = f"""### {i}. {entry['Error type']}**问题解释**:{entry['Explanation']}**原文**:{entry['Original']}**改正后**:{entry['Correction']}**差异标记**:{highlight_differences(entry['Original'], entry['Correction'])}""" results.append(result_item.strip()) # 去掉多余空格并加入到结果列表 # 将所有结果拼接为一个完整的字符串 return "\n\n---\n\n".join(results)def main(data: list) -> str: return {"result": display_corrections(data)}最后一步,输出最终错误。每个错误包括:
错误类型问题解释原文改正后的正确文本差异比较(删除或新增)搭建完成,发布使用最终的效果图如下。小编粘贴输入文字,点“运行”,等待 10秒钟,就可完成对文章错别字、标点符号和语法的检查,提高文字质量。

想一想,如果官网和公众号有错别字、语法错误,甚至有低级的标点符号错误,不仅影响用户阅读体验,也是对品牌形象的巨大伤害。
最后我把整个流程的 DSL 文件导出来,毫无保留,放在百度网盘,你可以直接下载:https://pan.baidu.com/s/1_546wrK086k4apsn_xIfHg?pwd=bw8m
下载后,导入到你的 Dify 中,直接就可以用。
希望对你有用。
全文完,如果你觉得有启发,就点个赞呗。
