蔚来的NIOIN 已经过去两周了,突然发现有一篇解读还没发。
这两天出差,刚好在看李飞飞的《我看到的世界》,有种神奇的一致性。
李飞飞在描述当时ImageNet (人工智能基建级别的数据集,可以说没有这个数据集就没有现在的人工智能)诞生时,提到当时如何通过对人类识别过程的观察,找到人类识别是以类别为基础的,逐步开始收集数据。
再通过一个语言数据集WordNet (一个世界词语数据库)的处理,筛选出人类几乎所有的名词,进而将对应的图片收集出来,产生一个足够覆盖度的数据库,包含1500万张图片。
在2015年,在ImageNet 上训练的 ResNet 出现,识别错误率为4.5%,首次低于人类。那时候神经网络的黑盒,对算力的要求,都被很多学者诟病,但是结果出来之后,浪潮势不可挡。
到今天,我们自动驾驶感知网络里面还有不少ResNet 的影子,很多任务依然是基于分类的识别,例如交通牌,红绿灯等等。
我们回到2024年,各家车企一直在讨论端到端,认为端到端能够带来自动驾驶更好的体验。
除去各家的各种细节差异,我们基本上可以认同,端到端即将原来轨迹规划的任务交给神经网络去完成。
这句话其实暗含的要求是: 神经网络要有思考和推理的能力。
这比当年李飞飞提出的基于分类的任务进了一大步。
蔚来的NIOIN 提出的世界模型基本上可以认为基于这种思考进行。那么如何获取这种能力。
我们想一下ChatGPT 是怎么获得巨大成功的,基于语言的上下文的理解,类似于将很多书都背下来,然后理解这些书,最后获取能力。
这也不难理解,熟读唐诗三百首,不会吟诗也会吟。
如果我们期待ChatGPT 时刻也出现在自动驾驶行业,应该怎么做?
蔚来WorldModel 就是类似的思路, 要找到一个能够尽量少标注,又能提供足够监督的任务。
视频生成并且推演。
就是有了这一个时刻的视频之后,推演出下一时刻的视频。并且由真实数据的下一时刻进行监督。
由像素的变化进行推演。
这种视频数据很容易获取,蔚来的群体智能那么多数据,可以不断回传数据来训练这个模型。
像素级别的理解能力,与传统自动驾驶技术栈上的物体目标级别的理解能力不是同日而语了。
当然,蔚来这边也提到也可以用语言作为基础,来调整风格和天气,有理由相信也用了一个LLM 的模块,一起进行多模态的训练。
有了像素的理解能力,再将轨迹作为监督,将理解和推演能力移植到驾驶任务上。
这是蔚来NIOIN 展现出来的野心。
必须要承认这件事情非常非常难,几乎摒弃了所有的自动驾驶原有的技术栈。用一种完全不一样的思路在思考自动驾驶,并且实施。
我看到的时候,目瞪口呆。
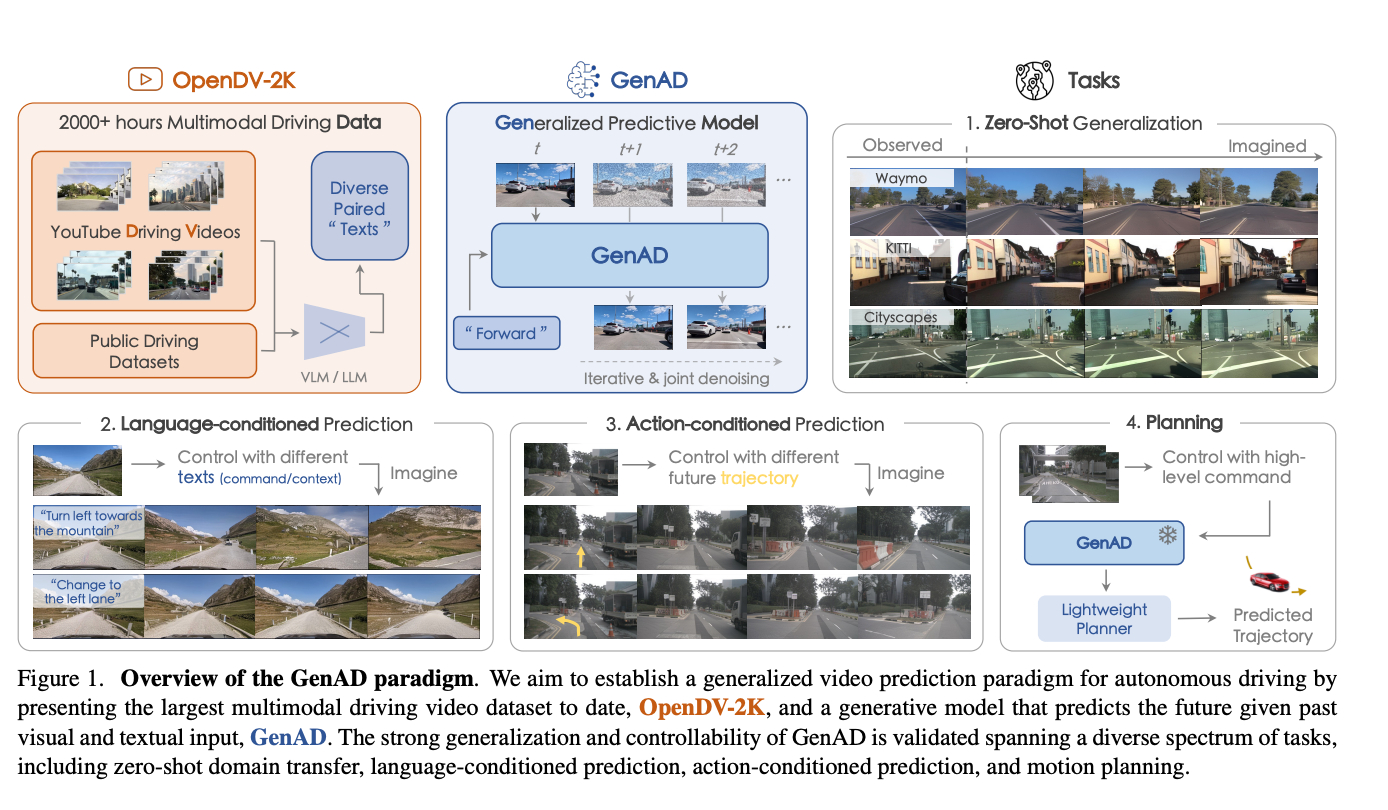
当然这也并不是没有先例,例如Generalized Predictive Model for Autonomous Driving 就有非常相似的思路。
最后,一定会有人批评黑盒,下限低之类的。我补充一句,连ResNet 当时出来的时候也有人说下限低。
PS: 李飞飞的自传,非常值得一读(这个时候不上个链接好像对不起我的广告,我没有合作,那没事了)