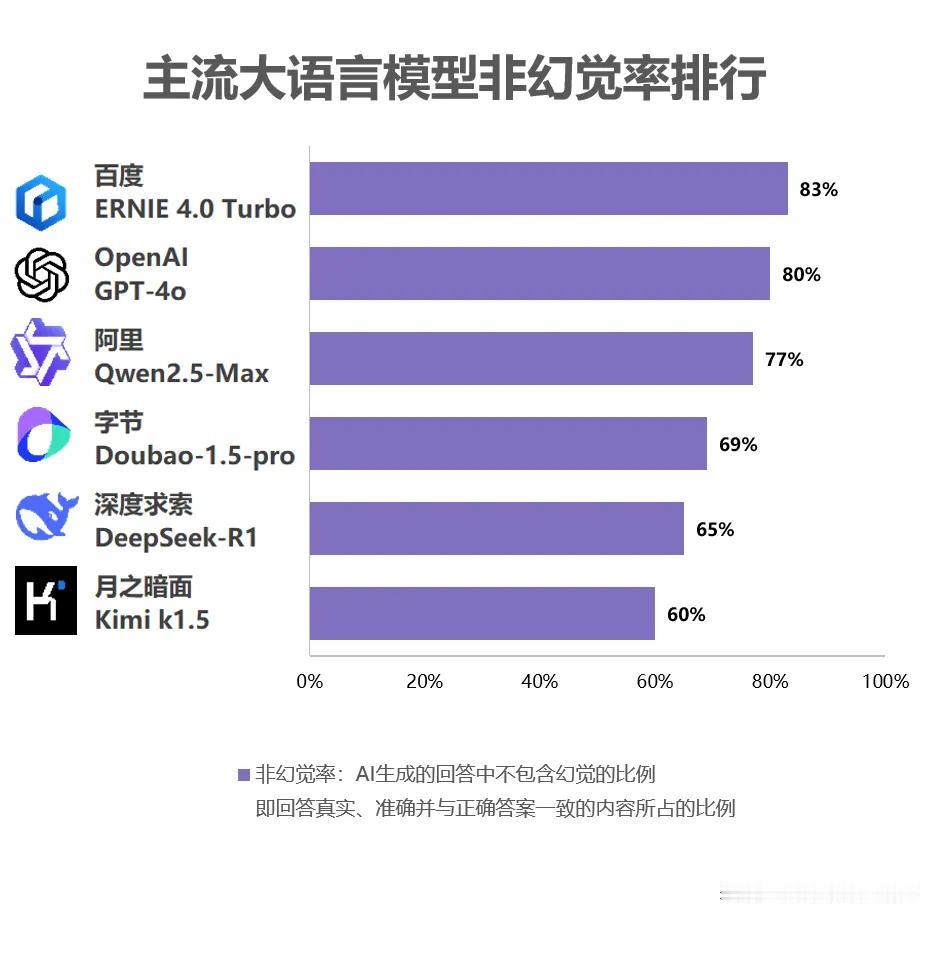
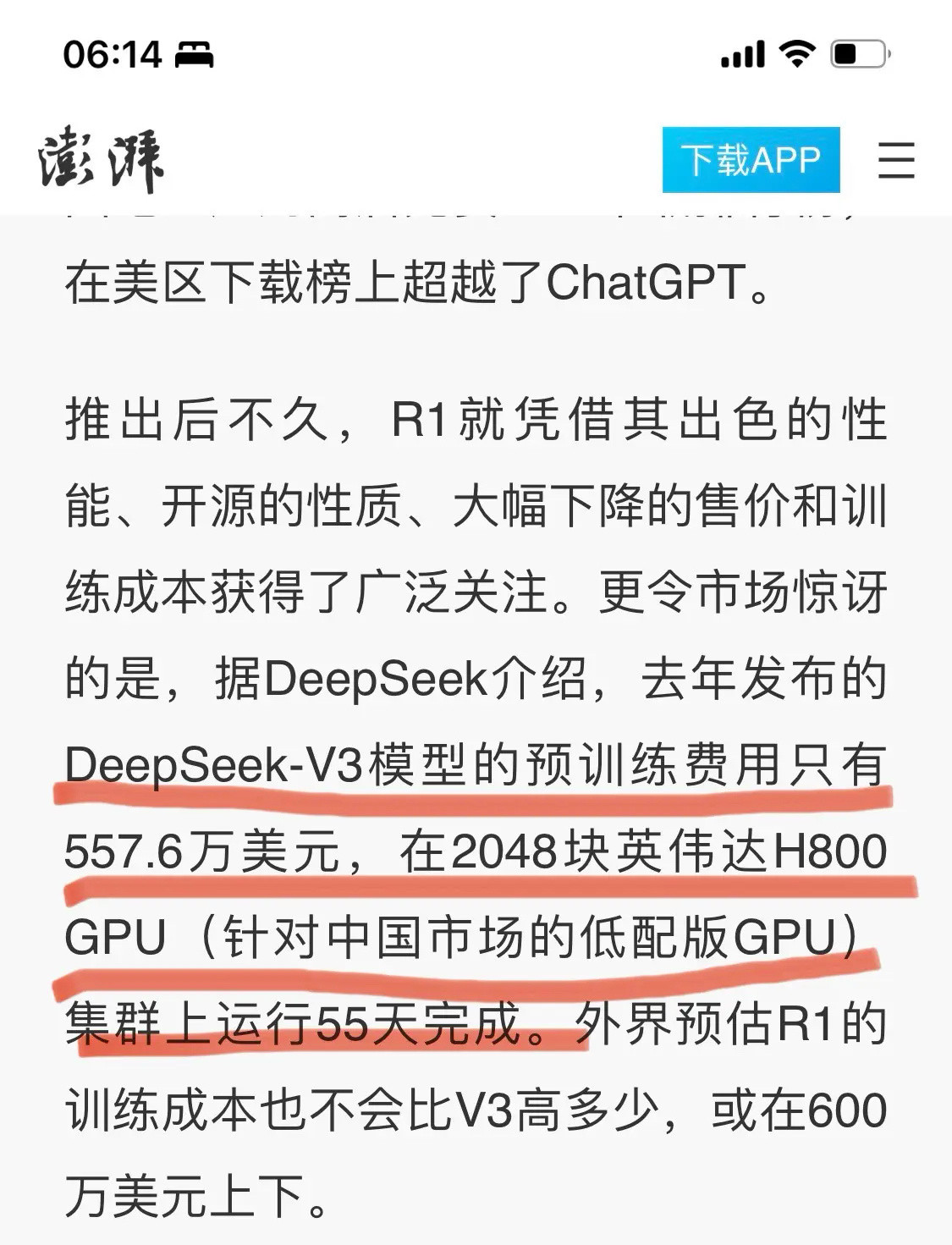
“当红炸子鸡”DeepSeek,在6大主流大模型幻觉评测中排第五,当下人们对AI有多挑剔? DeepSeek爆火后,不少专家给出了看法,重庆大学软件工程系主任雷晏就表示:DeepSeek在中文处理、数学推理、编程辅助等领域的效果,甚至高于了ChatGPT。可正当大家在为AI生成能力得到大步提升,感到赞叹的时候,一盆冷水却浇醒了我们,就是模型幻觉问题,还没有解决。 什么是模型幻觉呢?简单来说,大语言模型在运行时,靠的是概率预测机制来生成文本,预测下一个最可能出现的词汇,全网收集数据资料等。可有些网络信息是错误的,或许久未更新的,导致被AI东拼西凑,这也是很多人吐槽AI不靠谱的主要原因。 最近,有机构就对国内外6大主流大语言模型进行了幻觉评测,结果呢?近段时间呼声最高的DeepSeek排第5,非幻觉率约65%,而效果最好是文心一言,以非幻觉率接近83%力压GPT-4o !那文心一言是如何尽量减少幻觉的呢? 其核心在于百度的RAG技术,具备中文深度理解、多模态检索、垂直领域定制化以及实时数据整合能力等优势,很好的减少了ai幻觉问题,就算与OpenAI对比,也能明显看到文心RAG领先性。 此外,从文心大模型调用量来看,截止去年11月,文心大模型日调用量已经超了15亿,正所谓群众的眼睛是雪亮的,一方面文心靠谱,用的人多;另一方面,用的人多意味着每天有大量用户在帮助它训练,才能使其更懂内容的流畅和文字的意思。 现在看,每个大模型都有自己擅长性能。可模型幻觉,依然是所有大语言模型必须面对的问题!






豹哥
扯淡,5毛到手了没有?
火的天空
说DeepSeek的模型幻觉是一个严肃问题。严肃不过3秒,一说到文心一言,怎么突然变成了一个搞笑贴了