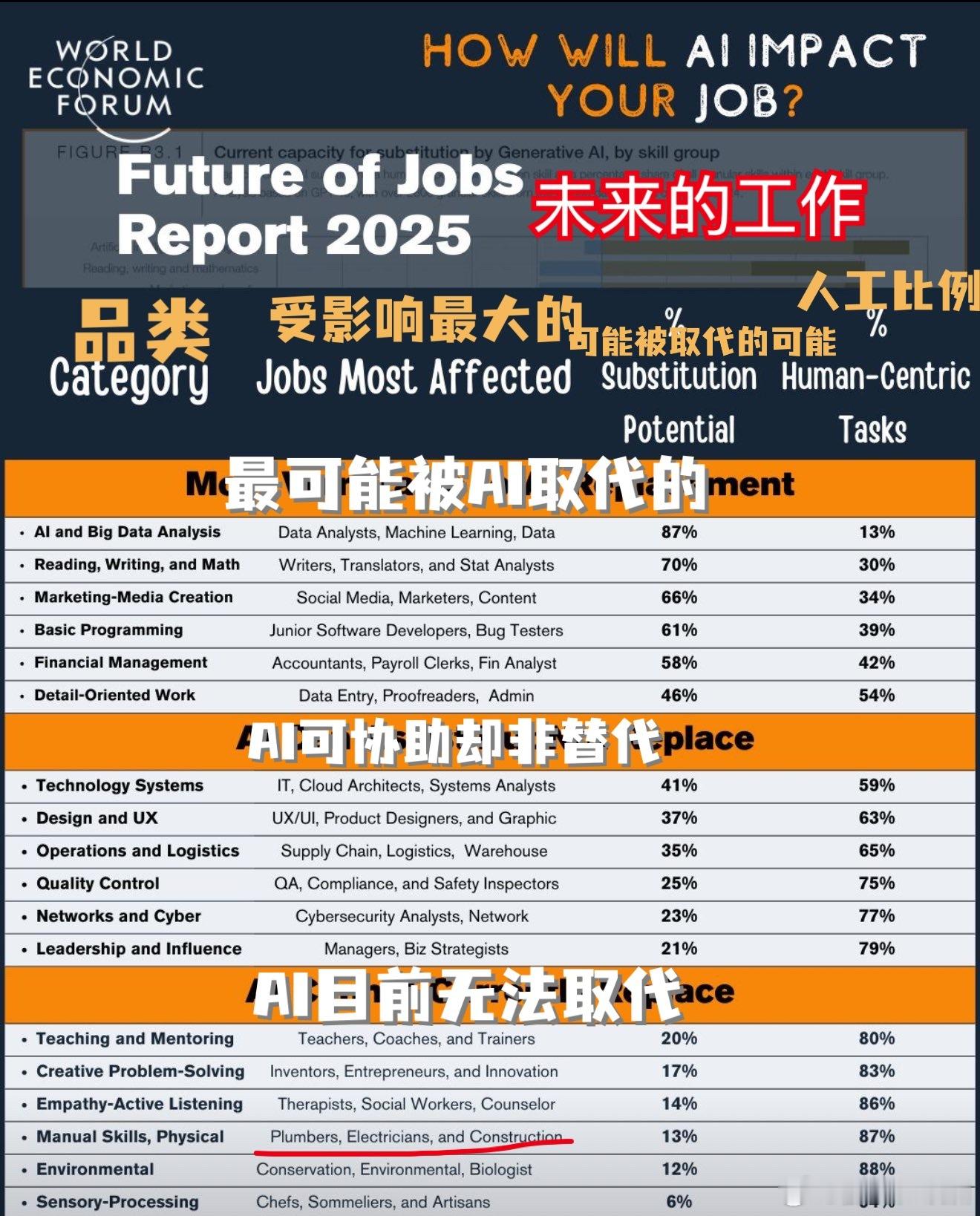
【如何评价AI到底强多少?】
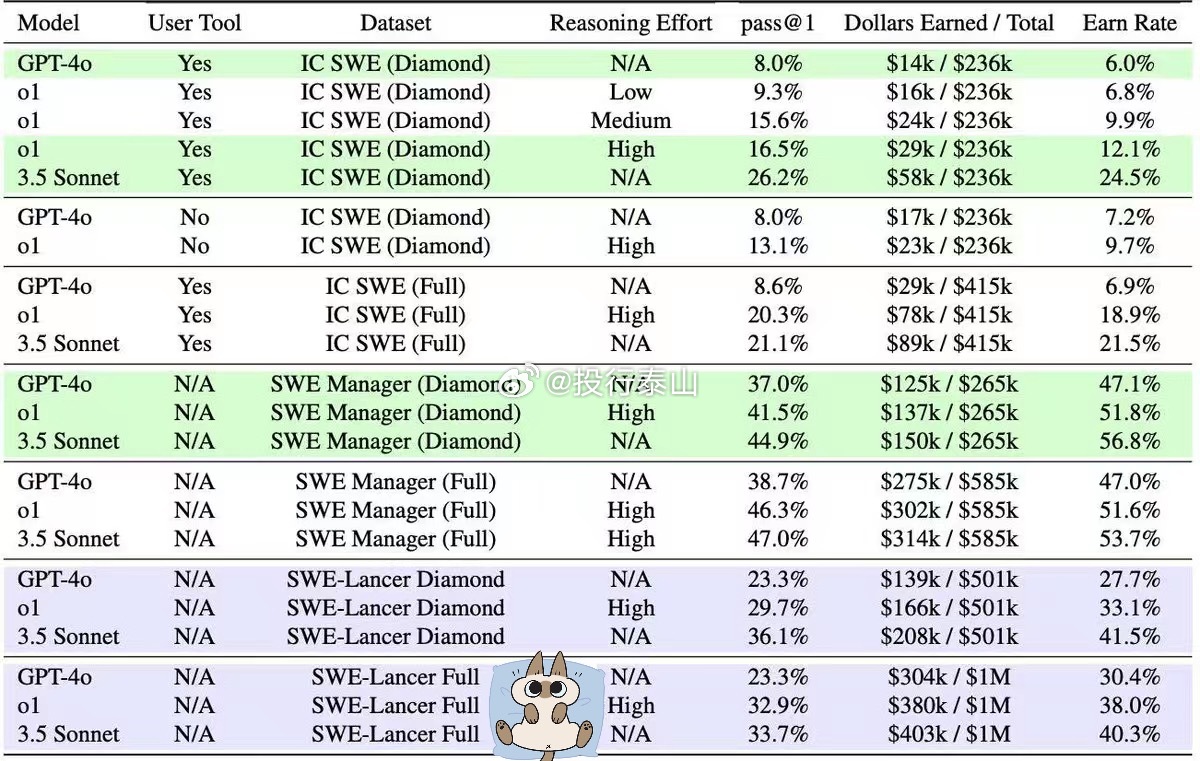
OpenAI推出最新的测试方法SWE-Lancer,用实际Upwork上的软体外包任务,总价值100万美元,窥探不同模型的AI到底能实际赚到多少钱。
AI任务与价值挂钩:SWE-Lancer的创新点位于它首先将AI模型的表现与真实价值挂钩。这些任务报告独立工程任务和管理任务的类别:独立工程任务范围从50美元的简单错误修复到3.2万美元的新功能开发;管理任务则要求模型在多个技术提示中选择最佳方案。独立工程任务使用专业工程师开发的最终测试进行评估,管理任务则与原始工程经理的选择进行比对。
研究结果:AI还不能取代,但已经从人类的动手能力抢下40%收入评估结果显示,即使是最先进的语言模型在处理大多数任务时仍然面临挑战。表现最好的Claude 3.5 Sonnet在SWE-Lancer Diamond测试集中获得了26.2%的独立工程任务通过率和44.9%的管理任务通过率,总共获得208,050美元。在完整的集中测试中,该模型获得了超过40万美元,但距离100万美元的总奖金增加了显着差距。这个测试有趣的地方是,有推理的o1还是给Claude 3.5 Sonnet.