上海人工智能实验室的新研究,通过引入 TTS 策略(Tree-Trace Search,树状搜索策略),探索小模型在特定任务上超越大模型,
1. 小模型的逆袭
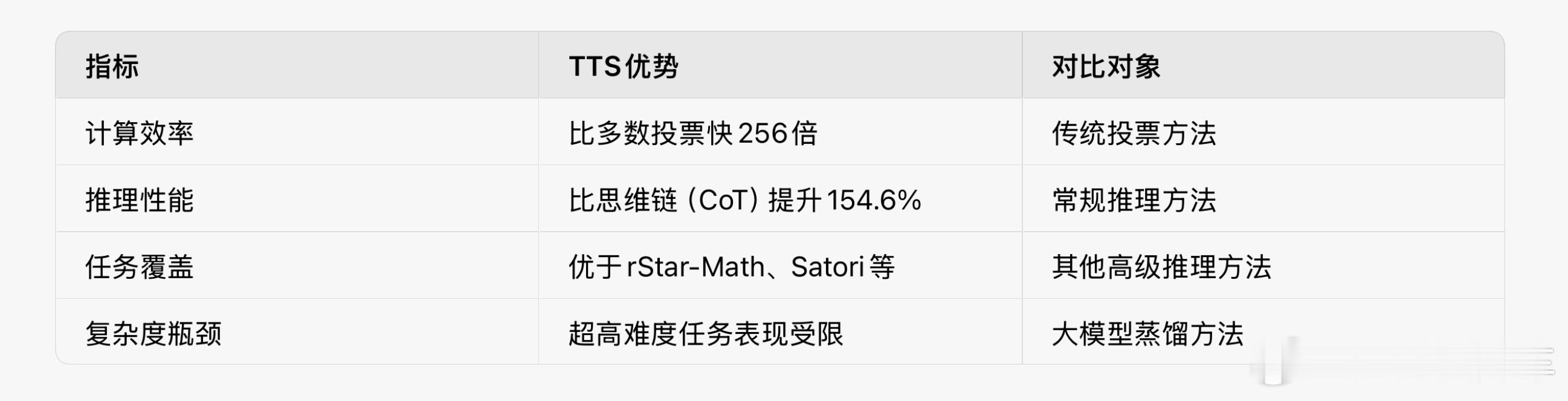
• 小模型可超越大模型:通过计算优化的TTS策略,3B参数的模型在数学任务(如MATH-500、AIME24)上表现优于405B模型,甚至0.5B模型可超过GPT-4o。
• 资源效率:小模型资源消耗减少100 - 1000倍,验证了“模型规模并非唯一决定因素”。
2. TTS的极限与适用性
• 模型规模影响:TTS对小型模型提升显著,但随着模型增大(如千亿参数以上),其优势逐渐减弱。
• 问题难度适配:
• 简单问题:Best-of-N等基础方法足够高效。
• 复杂问题:需多步搜索策略,但TTS在极高复杂度任务中仍逊于基于大模型蒸馏的方法(如DeepSeek-R1-Distill-Qwen-7B)。
3. 过程奖励模型(PRM)的挑战
• 奖励偏见:PRM可能因训练数据偏好(如倾向长回答或特定投票机制)给出误导性反馈。
• 动态调整需求:TTS需具备“奖励意识”,根据PRM特性调整策略,避免错误奖励信号影响推理。
优化策略的核心
• 奖励感知的TTS:动态适配不同PRM的反馈机制,避免因奖励模型与策略不匹配导致的性能下降。
• 分步验证增强:小型模型通过多步验证(如分解问题、逐步推理)弥补参数量不足,而大模型因独立推理能力强,适用更简化的策略。
• 应用场景:适合资源受限但需高精度推理的任务(如数学解题、逻辑分析),尤其是小模型部署场景(边缘计算、移动端)。
• 挑战:
1. PRM需针对性设计以减少偏见,否则影响TTS稳定性。
2. 复杂问题仍需依赖大模型的知识蒸馏或混合策略。
通过计算优化的TTS策略,小模型可在特定领域实现“以小博大”,但其性能高度依赖于奖励模型的设计、问题难度及策略适配。未来方向可能包括:
• 开发更鲁棒的PRM以降低偏见;
• 结合TTS与大模型蒸馏的混合框架,平衡效率与复杂任务处理能力。
这一发现为资源高效的人工智能系统设计提供了新思路。