阿里QwQ32B能否撼动DeepSeek地位最近阿里巴巴又搞了个大动作,发布了全新的推理模型通义千问QwQ-32B,并且直接开源了。
说实话,这事儿听起来有点不可思议——一个只有320亿参数的模型,居然敢说自己能和DeepSeek-R1这种拥有6710亿参数(其中370亿被激活)的大块头掰手腕?但阿里还真就这么说了,而且还拿出了数据来证明。
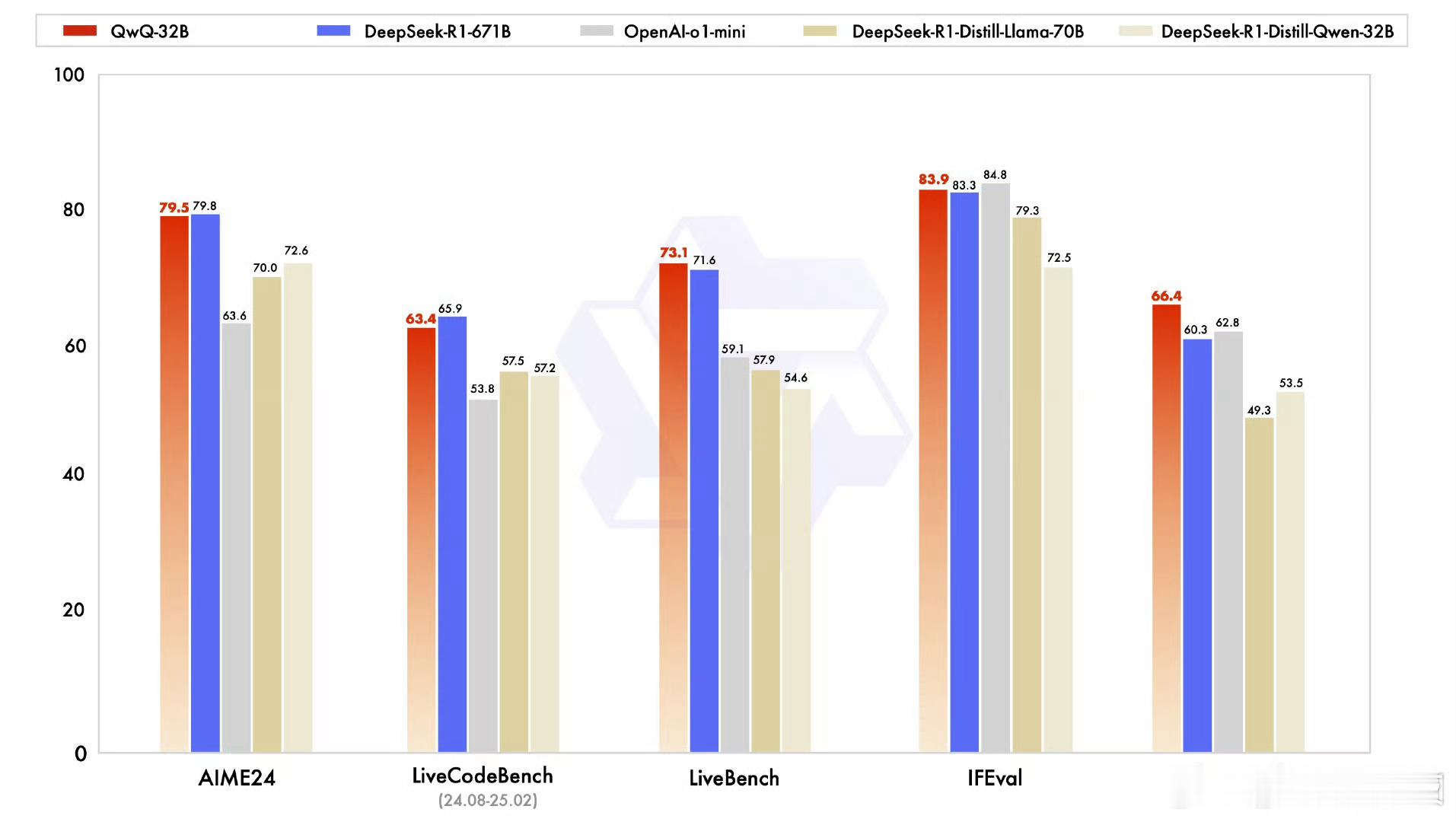
根据官方的说法,QwQ-32B在一系列基准测试中表现亮眼,涵盖了数学推理、编程能力和通用能力等多个维度。更夸张的是,它不仅和DeepSeek-R1打得有来有回,在某些评测集上甚至还占了上风。
比如,在测试数学能力的AIME24评测集中,以及评估代码能力的LiveCodeBench里,QwQ-32B的表现几乎可以与DeepSeek-R1平起平坐,完全碾压了OpenAI的o1-mini,以及同样尺寸的R1蒸馏版模型。
而在一些更复杂的评测榜单上,比如由Meta首席科学家杨立昆领衔的“最难LLMs评测榜”LiveBench、谷歌提出的指令遵循能力IFEval评测集,还有加州大学伯克利分校设计的BFCL测试中,QwQ-32B更是全面超越了DeepSeek-R1。
这种成绩,真的让人不得不服。
当然,光靠参数数量堆出来的性能并不稀奇,关键在于背后的技术突破。阿里团队这次特别强调了强化学习的应用,他们把这种方法用在了一个经过大规模预训练的基础模型上,结果效果出奇地好。
换句话说,QwQ-32B不是单纯靠“暴力计算”取胜,而是通过算法优化实现了质的飞跃。此外,阿里还在这个推理模型中集成了一些与Agent相关的能力,比如工具调用和环境反馈调整。
简单来说,这个模型不仅能思考问题,还能根据实际情况灵活应对,甚至可以在使用外部工具时进行批判性反思。
这就像是给AI装上了大脑+手脚的组合,既聪明又实用。
不过,最让我感兴趣的还不是它的性能,而是成本问题。
QwQ-32B的设计目标之一就是大幅降低部署和使用的门槛。开发者完全可以把它运行在消费级硬件上,轻松部署到本地设备中。
这对于那些预算有限的小团队或者个人开发者来说,简直就是福音。
说到这儿,我突然意识到,从2023年到现在,阿里通义团队竟然已经开源了200多款模型,覆盖了从0.5B到110B的不同参数规模,包括大语言模型千问Qwen系列和视觉生成模型万相Wan等两大基模体系。
显然,阿里的野心远不止是做一个单一的明星产品,而是要构建一个全模态、全尺寸的大模型生态。