努力用人话解释 VLA 是什么,和之前的端到端有什么区别。我觉得这也可能是目前解释得最清楚的文章。
首先,VLA 也属于「端到端」。
而现在我们常说的「端到端」,按照 VLA 的命名方式,其实可以算是 VA, 也就是输入视觉(V),输出动作(A)。它和 VLA 就差了一个 语言(L)。
而理想之前搞的 VLM, 按照 VLA 的命名方式,本质上就是 VL, 也就是输入视觉,输出语言。(M 是没有意义的,因为它代表的Model,跟占位符没什么区别)
这个 VL 不能输出动作,只是个「嘴炮」没法开车,真正输出动作开车的,还是一个 VA 系统,也就是大家都有的「端到端」。
一个 VL 一个 VA,
也就是理想说的「双系统」,慢思考和快思考。
而且,因为这个 VL 不能输出动作,所以想要真正让它起作用,也就还需要把 VL 输出的文本「转接」,才能输出给真正「开车」的 VA。
那这种转接具体是怎么实现的,在我印象里没有说过,但是毫无疑问肯定是有损失的,这种拼接并不是一个很好的解决方式。
那应该怎么无损拼接呢?
既然输入的还得是 V → 输出的还必然得是 A,
而且我们还有一个成熟的 LLM 语言模型。
那就用 L 把 V 和 A 连起来不就好了?
恭喜你,你想到的思路,其实就是 Google DeepMind 在 2023 年推出的,给机器人用的 VLA(Vision-Language-Action)。
通俗地说它就是用 L 把 V 和 A 更好的连接在了一起,因为 L 的存在,可以提供更明确的上下文,也就能把复杂指令或者长时间的决策过程纳入决策考量。
因为把 L 作为了「中间件」,所以 VLA 就有了 VA 实现不了的几个优势。
第一,VLA 它可以被设计为能输出显性的思维链,也就是俗称的「推理能力」,类似大家用 DeepSeek 开的深度思考。
传统 VA 模型是直接学习输入-输出映射,它知道「看到静止车辆要绕过去」,但不知道为什么绕。
所以在直行路口遇到静止车辆压实线也会去绕,因为它没有思维过程,只有条件反射。
虽然 VA 模型在某些情况下可能表现出类似推理的行为,但这通常是隐式地编码在网络权重中,这种高维度的信息,人看不懂,也就难以解释和控制。
VLA 不一样,它可以在做出决策之前通过人类语言「模拟思考」。
比如:「前方有静止车辆——是不是障碍物——前方是路口——不应该压实线绕行——选择等待」。这种「模仿推理」的能力,让它不仅知道要做什么,还知道为什么这么做。
第二,因为它有模仿推理的能力,并且可以解释,所以它也就非常适合在后训练阶段引入强化学习。
为什么这么说?
强化学习本质上是试错和反思的过程。但如果模型没有思维链,它在面对「奖励信号」时,不知道是因为哪一步行为好还是不好,
它只是「模仿者」,缺乏理解能力,也就无法调整策略,只能继续「盲模仿」。
而 VLA 有语言解释和模拟推理的中间层,当它在 RL 训练中获得反馈时,它能够「反思」:
我刚才为什么选择这么做?得到了负反馈,是因为推理中哪一步出现了偏差?下一次遇到类似情况,我应该调整哪一个判断逻辑?
举个例子,传统 VA 模型学到的是:
「遇到静止车就绕行」
——无论是什么情况,都会绕。
而 VLA 在强化学习过程中可以调整为:
「遇到静止车先判断是否路口——如果是路口就等待,如果是非路口再绕行」
这种调整,就是强化学习在有「思维链」条件下可以实现的行为纠偏。
所以经过强化学习的 VLA 在遇到多个意外情况合在一起的复杂场景,就会比没有思维链没有强化学习的 VA 有更好的处理能力。
而且,因为引入了视觉和语言模型输入,VLA 在交互上可以实现一些新的玩法和功能。
传统的 VA 模型可能只能基于视觉输入做出反应,但 VLA 可以通过语言进行更自然的交互。比如说我们可以用自然语言命令车辆:简单的比如「去最近的加油站」或「在路口减速」
长时间的、复杂的指令,理论上也可以识别:「请带我到前面十公里的商场,但如果看到交通堵塞就绕道走」。
因为系统不仅处理视觉数据,还能综合理解语言指令。
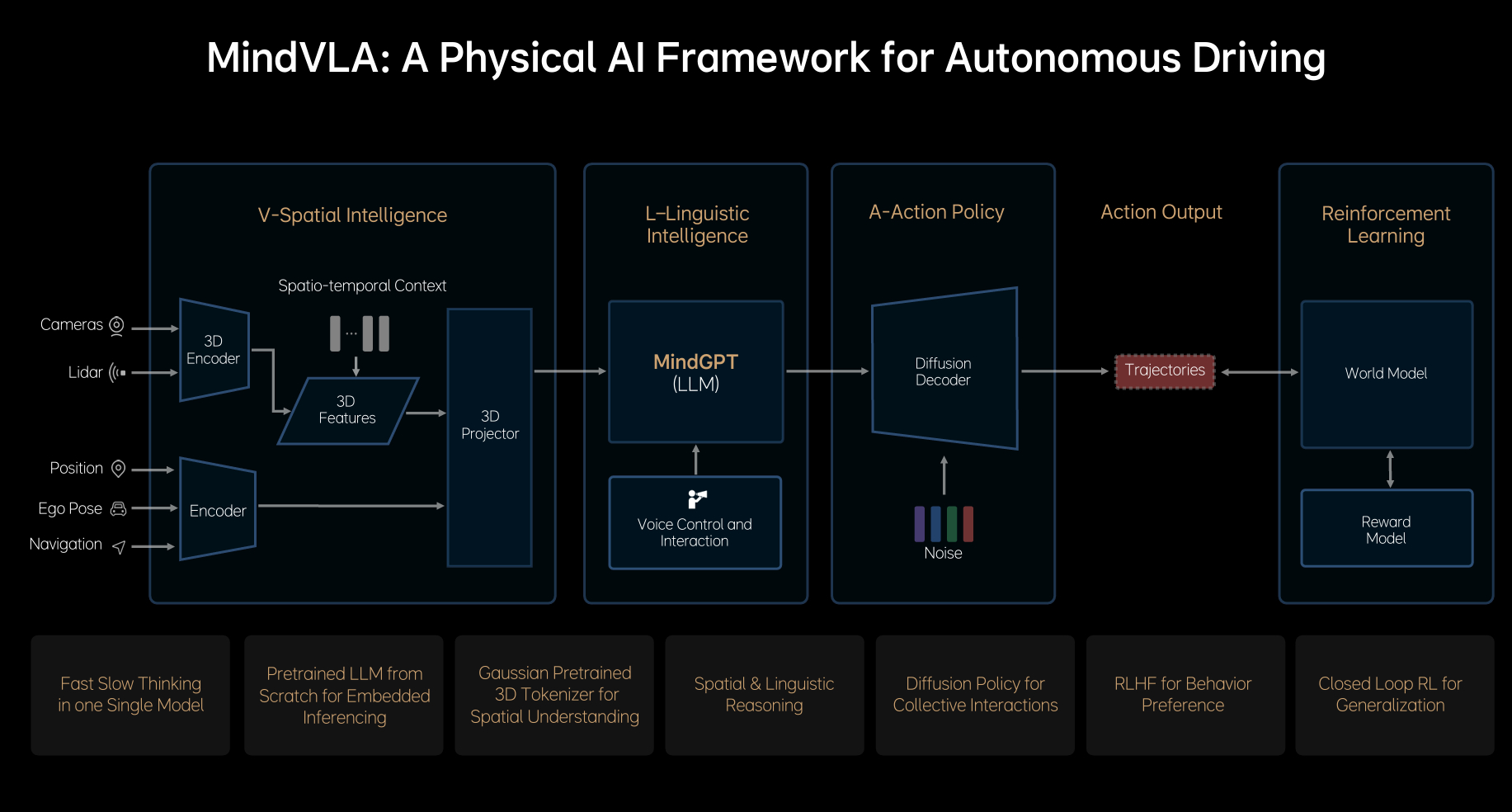
当然,VLA 虽然叫 VLA, 实际输入的信息肯定不只是 V(视觉)的,理想自己的 PPT 也写了它输入的包括摄像头、激光雷达、定位、自车位置和姿态信息,导航信息(图2)。
所以虽然理想演示了一个拍照发给车,车就自己从地库开到地面找到人的 DEMO, 但它肯定还是要用到地图信息的,至少出地库和开到定位附近都要有导航,快到目的地之后才切换到照片匹配为主。
隔壁元戎的 DEMO 就实在很多了,它就直接给出了目标信息,最重要的主要目标就是跟随导航前往目的地(图3)。
最后,VLA 虽然看上去很强大,
它依然有几个目前无法彻底解决的问题:
第一,幻觉依然存在。
LLM 和多模态模型天生会产生幻觉,VLA 同样如此。它有时候会「自信地胡说」,哪怕在决策环节,有时也会产生「看似合理,但其实错误」的决策逻辑。
比如明明前方路口不能左转,它还是可能因为某个奇怪的推理链条「觉得可以左转」。或者照片匹配失败时,信口胡编一个最接近的停车位置。这是 LLM 体系本身的内在缺陷。
第二,遇到未见过场景,依然可能懵逼。
虽然 VLA 引入了语言、推理和 RL,但本质上它的底层仍然是数据驱动的。没见过的场景、组合型极端情况,依然可能出现决策失败。
比如多个意外同时叠加(施工+交通管制+突发事故),场景组合超出模型经验范围时,它依然可能「想不出来」怎么做,直接停车都算好的。
第三,长链逻辑失效或不稳定。
虽然 VLA 引入了语言推理,但它的「思维链」本质上还是 token 级生成序列。
如果指令过长、条件太多,或输入视觉信息复杂,它的逻辑链条可能会断裂或混乱。
比如我们下一个 3 步嵌套条件指令「开到星巴克,途中加油,遇堵车绕行,优先走高架」。模型可能会执行 70%,但剩下的 30% 它可能理解错了。越复杂的条件组合,出错概率越高。
第四,算力有限。
VLA 理论上可以实时感知、语言推理并输出动作,但现实里车上芯片算力有限,模型体量巨大,既要跑感知、又要跑 LLM Prompt 推理、还要扩散解码出轨迹。
虽然 Thor 算力提升很大,但还是免不了要有很多蒸馏或者降低输入分辨率/精度的操作,那么这种「打折扣」跑起来的 VLA, 还有几成功力,咱们也不知道。
理想自己也说 VLA 并不是所有 A 都是经过 COT 思维链,而且要不要经过 COT, 还是模型自己决定的。
所以说:
VLA 确实把有思维链喝直接输出动作做进了一个模型里,理论能力相对于 VA 模型确实会更高,但它也存在自己的问题。
而且就像端到端有好坏一样,VLA 之中也有好坏,用了 VLA 就等于体验好吗? 我相信开过今年这么多「端到端」的车主,肯定深有体会。
智驾数码团