智能座舱进入“端到端”时刻...和大家聊聊座舱大模型|
今天到访商汤。
大多数人好奇,智驾端到端,那下半场座舱会带来什么?
高通下代芯片规划算力是 200+TOPS,能够支持 4-5 个 7B(亿)的参数模型,座舱的“端到端”时刻也马上到来。
未来座舱多模态大模型会变成多个应用智能体,智能体和智能体之间可以交流、推理,满足用户不同需求,和如今的智驾系统 1 + 系统 2 相同。
也是同样端到端,这时候最大的改变就是系统从过去的被动接受人类指令,变成更类人的主动交互、和人一样丝滑交流。
商汤多模态流式交互前段时间比较火,多模态就是集成了多种交互信息,比如声音、文本、图像和视频等等,实时交互,具有推理性。
这种交互模式有几个特点,比如多任务的适应性强,能够在一个模型中处理多种任务,并且根据不同上下文调整行为和输出,其次是具备记忆力。
跑在座舱上有几个好处,多模态那可以利用舱内的 DMS/OMS 摄像头,结合车内场景来调动舱内的状态场景理解能力更强,而且大模型的交流会更类人。
具备记忆力的优势是比如乐道的「小乐识人」,就是用了商汤的方案。可以基于人脸数据自动存储个性化数据,叫小乐后就会记住你的使用习惯、座椅位置等等。
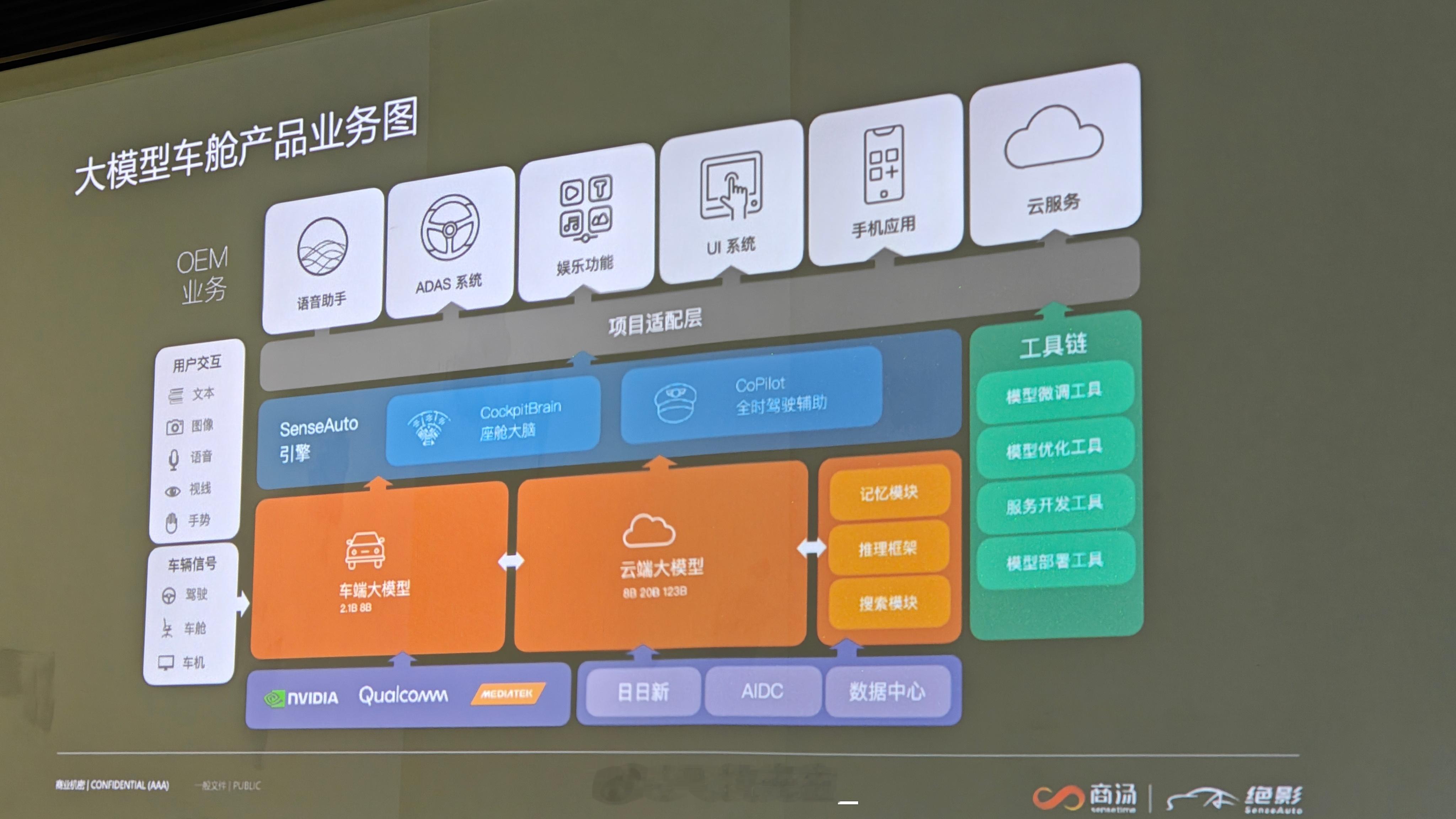
现在商汤有两种座舱模型:
车端的座舱模型参数大概是 2.1B/8B ,8295 可以支持 2.1B ,8B 的参数得 Orin 才可以 。几十 B 甚至到 100B 以上就得上云端算力。
而我们现在车上大部分语言跑的都是单模态,只懂语音,模型也很小,小于 1B ,主要做车控识别。
而且过去语音都是有很多个小模型堆叠一起,然后翻译成文本再分类,但会常常识别不清晰,或者识别错了,要么识别不了。
未来多模态的大模型,就是可以通过舱内视频+语音+场景等方式结合,识别更加准确、也有更拟人化的识别,而且还有时序的记忆。
比如在车里掉了一顶帽子,语音会告诉你“你之前掉在了后排的座椅上。”
比如丢了手机,语音会说”昨天早上十点有个长发的女生把手机落在前排座椅了”
但不同模型体量带来的方向不同。
云端前期投入不高,但后期量产成本很高,多模态的语音、图片、视频等算力需求很大。
车端相反,前期投入高,比如要大算力芯片。但后期推理成本低。
#商汤科技##新能源汽车##大v聊车#