强化学习 (RL) 已成为微调大型语言模型 (LLM) 以符合人类偏好的基石。在 RL 算法中,近端策略优化 ( PPO)因其稳定性和效率而被广泛采用。然而,随着模型变得越来越大并且任务变得越来越复杂,PPO 的局限性(例如内存开销和计算成本)促使人们开发更先进的方法,例如组相对策略优化 ( GRPO )。
在此博客中,我们将介绍以下内容:
重新认识 PPO,
解释它如何融入法学硕士 (LLM) 培训流程,
深入了解 GRPO
LLM 培训中的强化学习
RL 在 LLM 培训中处于什么位置?
下面是一个简化的架构图,展示了 RL(PPO/GRPO)在 LLM 训练流程中的位置:
1. 监督微调(SFT)
在该流程的第一阶段,模型会根据高质量的人工编写演示数据集进行微调。这通常需要一组人工标注员创建一个数据集,该数据集主要由来自其他模型的提示以及一些标注员编写的提示组成。这种初始微调产生了所谓的 SFT 模型 (π_SFT),该模型可作为进一步优化的基线。 图二
2. 奖励模型
第二阶段涉及创建一个可以评估模型输出质量的“奖励”模型。通常,会收集成对比较的数据集,其中人类标记者表明他们对相同提示的不同模型输出的偏好。这些比较数据用于训练奖励模型 (R),该模型可以预测人类更喜欢哪些输出。这是一个至关重要的步骤,因为它创建了一种根据人类偏好评估模型输出的自动化方法,本质上将人类判断转化为可用于强化学习的标量奖励信号。
2. 奖励模型
第二阶段涉及创建一个可以评估模型输出质量的“奖励”模型。通常,会收集成对比较的数据集,其中人类标记者表明他们对相同提示的不同模型输出的偏好。这些比较数据用于训练奖励模型 (R),该模型可以预测人类更喜欢哪些输出。这是一个至关重要的步骤,因为它创建了一种根据人类偏好评估模型输出的自动化方法,本质上将人类判断转化为可用于强化学习的标量奖励信号。
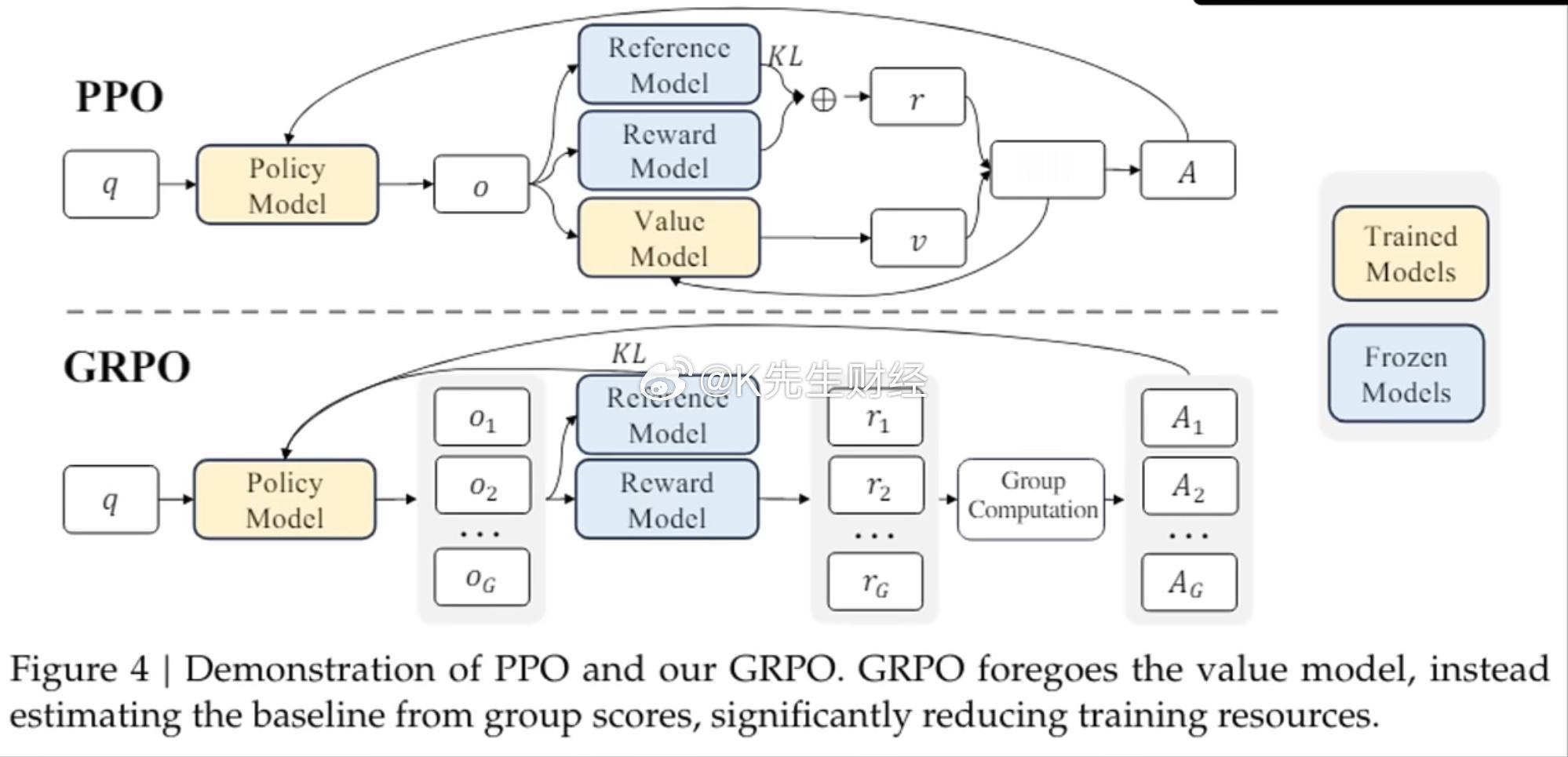
最后阶段使用强化学习,通过近端策略优化 (PPO) 算法优化模型的策略 (π_θ)。该过程分为三个步骤:
该模型生成对提示的响应
这些反应由奖励模型评估,以计算奖励
然后优化策略以最大化这些奖励,同时保持接近原始 SFT 模型的行为
这个过程可以随着时间的推移不断迭代,从最新策略中收集新的比较数据来训练更新后的奖励模型,然后使用这些数据来训练新策略。研究人员指出,虽然他们的大部分比较数据来自监督策略,但有些也来自PPO策略,这表明这是一个迭代改进过程。
这种“对齐过程”允许模型根据项目中标注者的偏好遵循书面说明。对齐还可以用于其他目的,例如输出“更正确”的输出或毒性较小的输出。