科技大佬谈 deepseek
Lex Fridman的访谈涵盖了DeepSeek的技术突破,特别是V3和R1模型的细节,以及中国AI生态系统的崛起和全球AI竞赛。DeepSeek模型分为预训练和后训练阶段,分别优化不同功能,并介绍了创新的混合专家模型和低秩注意力机制。此外,访谈探讨了开放权重的隐私和安全性问题,AGI的未来进展,以及AI对地缘政治的影响,特别是美国的AI出口管制。
- 🧠 **DeepSeek V3与R1模型概述**:DeepSeek V3是通用聊天模型,R1专注于推理任务,性能与OpenAI GPT-4相当,且都开放权重。
- 💻 **后训练方法**:DeepSeek采用指令调优、偏好调优和强化学习调优等方式来优化模型,尤其R1侧重于推理任务。
- 🔐 **数据隐私和安全性**:虽然模型本身不会窃取用户数据,但用户在使用时需要信任托管方,避免数据泄露风险。
- 🧑💻 **推理过程的两阶段生成**:DeepSeek R1通过详细的思考过程先推理再给出最终答案,提升了推理准确性。
- ⚙️ **混合专家模型和低秩注意力**:通过减少激活参数数量,提升了训练和推理的效率,降低了计算成本。
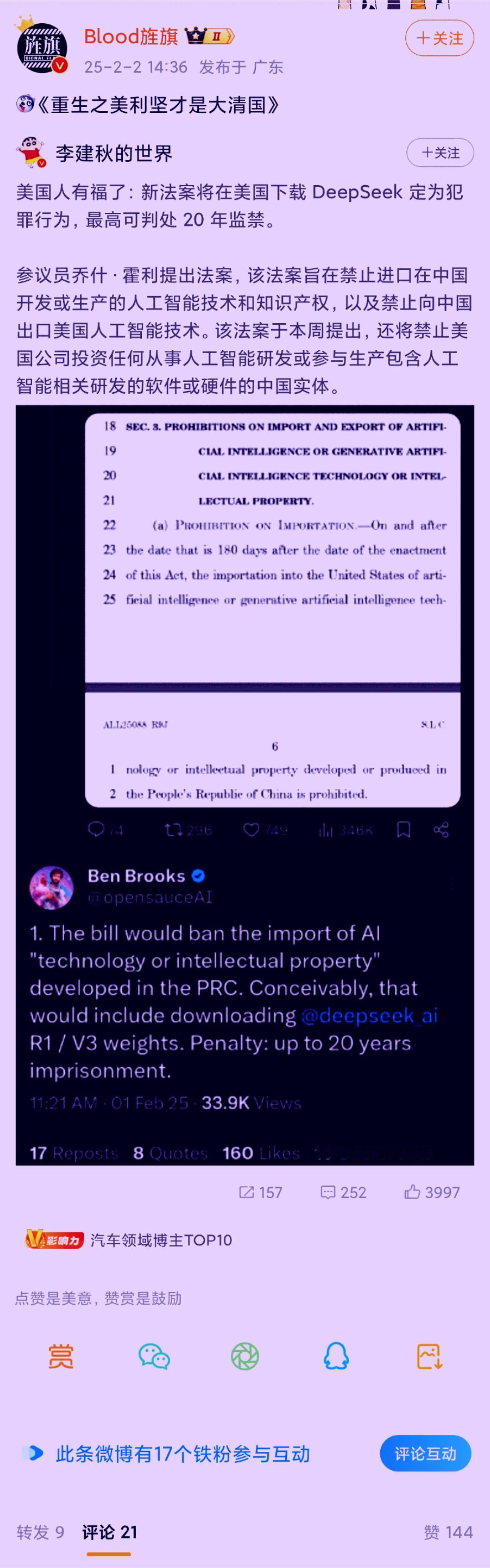
- 🌍 **AGI与地缘政治**:预计未来AGI将具有巨大的地缘政治影响,特别是计算资源的使用和美国的AI技术出口管制。
- 🔬 **技术突破与挑战**:在训练过程中,DeepSeek通过改进路由机制和GPU通信优化,显著提高了效率。
Q: DeepSeek V3和DeepSeek R1有什么区别?
A: DeepSeek V3是一个通用的聊天模型,适用于各种应用场景,如问答系统和编程助手,能够生成高质量的、格式化的回答。而DeepSeek R1则专注于推理任务,能够生成详细的推理过程,适用于需要复杂推理的任务,比如数学问题求解和代码调试。
Q: DeepSeek模型的训练阶段是如何进行的?
A: DeepSeek的训练阶段分为预训练和后训练两个阶段。预训练通过自动回归预测,主要使用大规模互联网文本数据进行训练。后训练则采用多种优化方法,如指令调优、偏好调优和强化学习调优,以优化模型的特定行为,提升模型的性能和适用场景。
Q: 什么是DeepSeek R1的两阶段推理过程?
A: DeepSeek R1采用两阶段推理过程,首先生成一个详细的思考过程,并逐步解释问题,分解为多个步骤。然后,在模型完成推理后,会通过一个特殊Token标记开始给出最终答案。这一过程与OpenAI等公司采用的分步骤展示方式有所不同,更为集中和自动化。
Q: DeepSeek R1在计算效率上有哪些创新?
A: DeepSeek R1采用混合专家模型(MoE)和多层低秩注意力(MLA)技术,减少了训练和推理时的计算成本。通过激活特定任务所需的子模型,减少了不必要的计算,显著提高了效率。此外,还优化了GPU间的通信机制,提高了模型在训练中的资源利用率和推理速度。