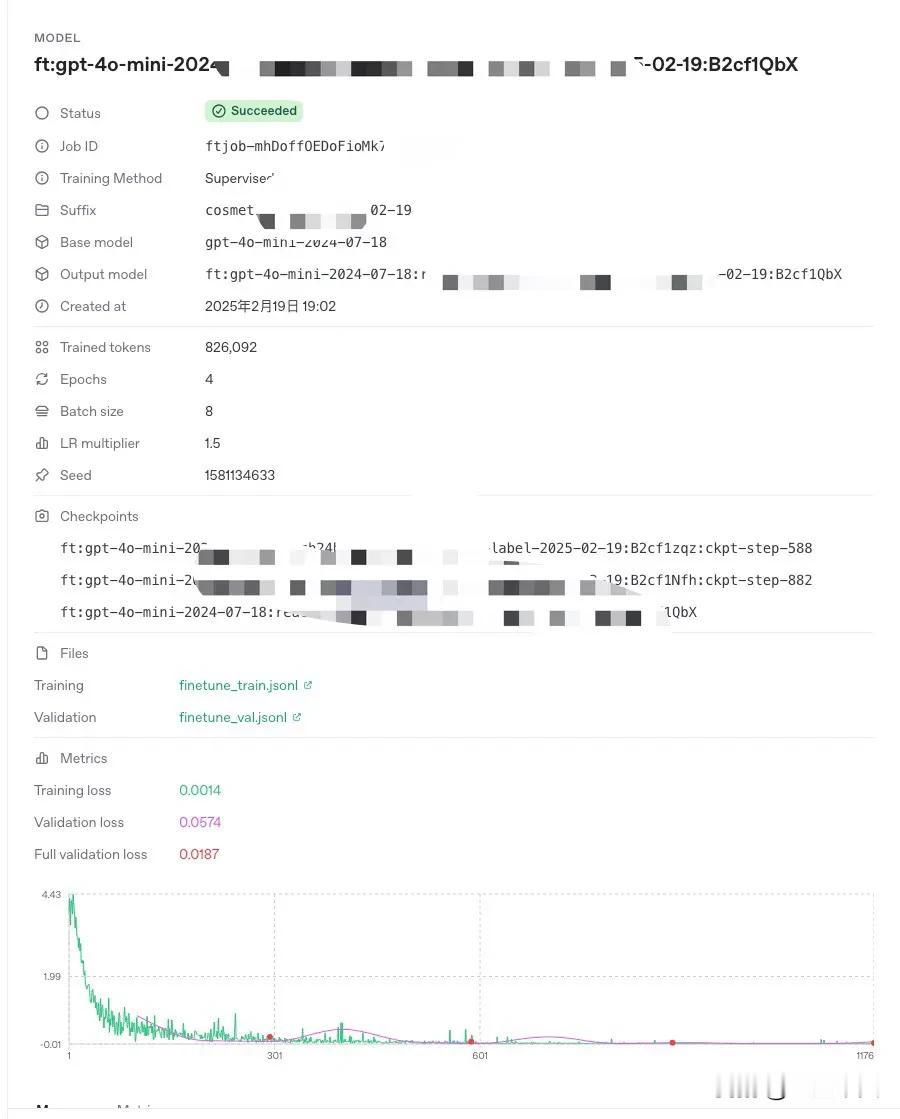
终于,微调取得了阶段性成果… 感谢 DeepSeek R1,为我解答了改进微调结果的众多疑问,让我有了改进的方向。 我的微调基于 OpenAI gpt-4o mini,大概 3000 条数据,今天微调取得了非常好的效果,训练损失和验证损失都非常低,一条非常漂亮的曲线🤩。 经过实际测试,幻觉率控制的非常低,在我们的评估中,取得了 4.6/5 分的成绩。 R1 的思考过程,非常有价值,看着它的思考,你会明白很多逻辑和道理,这是答案所给不了的。 把前面几次的微调参数和结果(评估分在 2.2-3.7 之间),告诉 R1,让它总结规律该如何设置微调参数,同时把自己的数据示例,让 R1 分析如何构造数据集可以提升效果。 R1 给我的启发是: 1、我的案例,超参数的推荐设置为:训练3-5 轮,适当调大批次大小到 6-8,学习率推荐 1.2-1.5。 2、最重要是数据,增加多样化数据,包括同义词替换、多角度提问、对比型问答、情景判断、错误修正型问答、组合问题、多语言、多轮次问答等等。 关于第二点,看着很复杂, 其实也有规则,我让 R1 写成 Python 代码,然后在 Cursor 里优化完善,只花了 1-2 小时,3000 条高质量、多样化的数据就完成了。 马上提交微调,大概花了 30 分钟,微调就完成了。效果超越预期,预期评估得分提高到 3.8-4.2 分,没想到直接获得了 4.6 分。